วิธีที่ 1 ใช้ deepcut
หัวข้อนี้เราจะมาตัดคำภาษาไทย (word tokenization) โดยใช้ AI (Deep learning) ของบริษัท True กันดีกว่า ซึ่งทีมวิจัยเขาใช้โมเดลแบบ CNN (Convolutional Neural network แบบ 1 มิติ) มาทำนายด้วยวิธี binary classification (ทำนายว่าตัวอักษรตัวนี้ มันเป็นตัวเริ่มต้นของคำหรือไม่)

โดยทีมวิจัยเขาเทรนจากข้อมูลของ NECTEC (ประกอบด้วย บทความ, ข่าว, นิยาย และ encyclopedia) ใครสนใจก็ดาวน์โหลด Dataset ตามนี้ ซึ่งเขาจะแบ่งข้อมูลออกเป็นชุดฝึกสอน 90% และ ชุดทดสอบ 10%
ประสิทธิภาพของโมเดล
- f1 score: 98.8%
- precision score: 98.6%
- recall score: 99.1%
ทั้งนี้ทีมวิจัยจาก True เขาเตรียมมอดูลชื่อ deepcut ให้เราแล้ว โดยจะใช้ภาษา Python ในการพัฒนา ซึ่งวิธีติดตั้งใช้งานเท่าที่ผมลองดู ก็จะเป็นขั้นตอนแบบนี้
- ติดตั้ง Anaconda
- จากนั้นไปที่ command line แล้วติดตั้ง Tensorflow ด้วยคำสั่ง
pip install tensorflow
- ติดตั้ง Keras ด้วยคำสั่ง
pip install keras
- ติดตั้ง deepcut
pip install deepcut
ตัวอย่างวิธีเขียนโค้ด 3 บรรทัดแค่นี้แหละ ง่ายมากจุงเบย
import deepcut
list_word = deepcut.tokenize('ตัดคำได้ดีมาก')
print(list_word)
output ที่ควรจะออกทาง console ได้แก่
['ตัดคำ','ได้','ดี','มาก']
แต่เนื่องจาก console มันแสดงภาษาไทยไม่ได้ ผมเลยต้องให้ output เขียนลงไฟล์แทน ด้วยเหตุนี้จึงต้องเขียนโค้ดใหม่เป็น
import deepcut
list_word = deepcut.tokenize('ตัดคำได้ดีมาก')
file = open("ouput.txt","w")
file.write('|'.join(list_word))
เมื่อไปเปิดไฟล์ output.txt ที่สร้างขึ้นมา ก็จะได้ประมาณเนี่ย
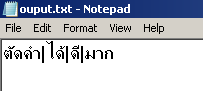
ลองดูประโยคปราบเซียน เช่น
'สาวตากลมมานั่งตากลมตากลมตากลม'
ก็สามารถแยกเป็น
สาวตา|กลม|มา|นั่ง|ตาก|ลม|ตากลม|ตากลม|
ลองสักอีกประโยคหนึ่ง
'สองสาวสุดแสนสวยใส่เสื้อสีแสดสวมสร้อยสี่แสนสามสิบเส้นส้นสูงสีส้มเสื้อสูทสีแสบสันสาดส่องแสงสีสดใส' (ที่มา)
ก็สามารถแยกเป็น
สองสาว|สุด|แสน|สวย|ใส่|เสื้อ|สี|แสด|สวมสร้อย|สี่|แสน|สาม|สิบ|เส้น|ส้น|สูง|สี|ส้ม|เสื้อ|สูท|สี|แสบ|สันสาดส่อง|แสง|สี|สดใส
2 ประโยคข้างต้นผมลองแกล้ง AI เล่นๆ อาจจะตัดคำไทยได้ไม่เนียนมาก ขนาดคนเองยังอ่านยากเลย
แต่ก็ขอปรบมือให้ทีมวิจัยในการคิดงานเพื่อคนไทย และคิดว่ามันพัฒนาต่อให้แม่นยำกว่านี้ได้อีกเยอะเลย
หลักการทำงานเท่าที่ผมแกะจากซอร์สโค้ดของไลบรารี่
สมมติว่ามีประโยคไทยดังนี้
'ตัดคำได้ดีมาก'
เมื่อ AI เห็นข้อความก็จะรู้ว่าประกอบด้วย
![]()
โดย AI จะมอง 1 ประโยค เป็นอาร์เรย์ของชุดตัวอักษร ในกรณีนี้ประโยค ‘ตัดคำได้ดีมาก’ จะเห็นเป็น 13 ตัวอักษร จากนั้น AI ก็จะบอกว่า ตัวอักษรไหนเป็นตัวเริ่มต้นของคำ ถ้าใช่ก็จะให้คำตอบว่า 1

รูปข้างบนตัวอักษรสีแดง เป็นผลลัพธ์จากการทำนายของ AI ที่ประกอบด้วยชุดของอาร์เรย์ 13 ตัว โดยที่เลข 1 บอกว่าคืออักษรเริ่มต้น (0 คือไม่ใช่)
แต่เพื่อความสะดวกตอนใช้คำสั่ง deepcut.tokenize(‘ตัดคำได้ดีมาก’) ฟังก์ชั่นก็จะตัดแบ่งคำออกมาให้เลยอัตโนมัติ โดยเบื้องหลังการทำงานจะใช้เทคนิคเลื่อนเลข 1 ในอาร์เรย์ไปทางซ้าย (ส่วนอักษรตัวสุดของประโยคก็จะระบุว่าเป็น 1 ไปเลย) ดังรูป

จากนั้นภายในไลบรารี่จะเริ่มไล่ตัวอักษร ตั้งแต่หมายเลข 0 กำกับ จนมาหยุดตรงตัวอักษรเลข 1 ก็จะถือว่าเป็น 1 คำไทย
ด้วยเหตุนี้เมื่อใช้คำสั่ง deepcut.tokenize(‘ตัดคำได้ดีมาก’) ก็จะให้ค่าออกมาเป็นอาร์เรย์ดังต่อไปนี้
['ตัด','คำ','ได้','ดี','มาก']
ผมลองสเก็ตรูปโมเดลของ Deep Learning ตัวนี้ใส่ในกระดาษ ปรากฏว่าซับซ้อนไม่ใช่เล่นเลยแฮะ (รายละเอียดไม่ลงลึกนะ ให้ดูเฉยๆ เป็นไอเดียเผื่ออนาคตเขาเปลี่ยนโมเดล )
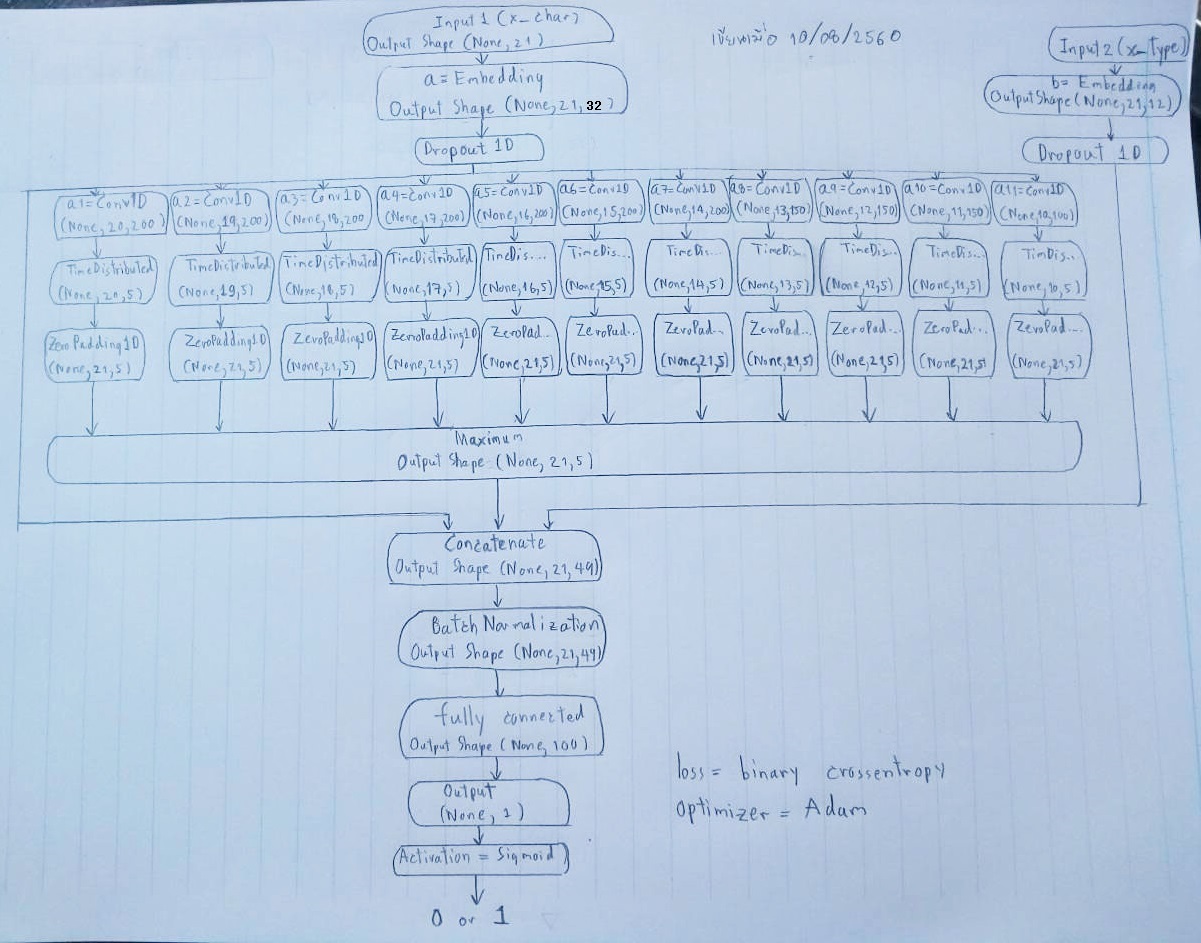
ใครสนใจซอร์สโค้ดบน Github ก็ตามนี้นะ
https://github.com/rkcosmos/deepcut
ดูตัวอย่างการทำงานได้ที่
https://rkcosmos.github.io/deepcut/
หมายเหตุ deepcut ตอนนี้ถูกผนวกเข้ากับ โมดูล pythainlp จึงสามารถเรียกผ่าน pythainlp ได้เช่นกัน
เริ่มต้องติดตั้งโมดูล
pip install pythainlp
ตัวอย่างการเรียกใช้งาน
import pythainlp
words = pythainlp.tokenize.word_tokenize('ตัดคำได้ดีมาก', engine='deepcut')
print(words)
output ที่ควรจะออกทาง console ได้แก่
['ตัด', 'คำ', 'ได้', 'ดี', 'มาก']
วิธีที่ 2 ใช้ thainlplib
จากบทความนี้ https://sertiscorp.com/thai-word-segmentation-with-bi-directional_rnn/ ของทีม Data Science จาก SERTIS เขาได้นำเสนอวิธีตัดคำภาษาไทยด้วยวิธี Recurrent Neural Network แบบสองทาง (bi-directional RNN) และเตรียมมอดูลชื่อ thainlplib ให้เราใช้งาน โดยข้อมูลที่ใช้สอนโมเดลก็มาจาก NECTEC
ประสิทธิภาพของโมเดล
- precision: 98.94%
- recall: 99.28%
- F1 score: 99.11%.
1) ขั้นตอนการใช้งานก็ไปดาวน์โหลดโค้ดไฟล์ zip ที่ลิงค์นี้ https://github.com/sertiscorp/thai-word-segmentation เสร็จแล้วก็แตกไฟล์ด้วย
ถ้าใครใช้ git เป็น ก็ใช้คำสั่งต่อไปนี้ เพื่อดาวน์โหลดโค้ดแทนก็ได้
git clone https://github.com/sertiscorp/thai-word-segmentation.git
อย่าลืมต่อเน็ตด้วยนะ พอทำเสร็จแล้วโค้ดจากโปรเจค ก็จะมาอยู่ใต้โฟลเดอร์ thai-word-segmentation ที่เครื่องของเรา
2) ก็ cd ไปที่โฟลเดอร์ thai-word-segmentation
cd thai-word-segmentation
3) มอดูลที่ต้องติดตั้งได้แก่
- Python
- TensorFlow
- NumPy
- scikit-learn
จริงๆ แล้วถ้าเราติดตั้งตามหัวข้อของ deepcut ก็ไม่ต้องลงอะไรเพิ่มเติม ใช้งานได้ทันที
4) จากนั้นก็เขียนโค้ดขึ้นมา จากตัวอย่างต่อไปนี้
from thainlplib import ThaiWordSegmentLabeller
import tensorflow as tf
saved_model_path='saved_model'
text = """ประเทศไทยรวมเลือดเนื้อชาติเชื้อไทย
เป็นประชารัฐไผทของไทยทุกส่วน
อยู่ดำรงคงไว้ได้ทั้งมวล
ด้วยไทยล้วนหมายรักสามัคคี
ไทยนี้รักสงบแต่ถึงรบไม่ขลาด
เอกราชจะไม่ให้ใครข่มขี่
สละเลือดทุกหยาดเป็นชาติพลี
เถลิงประเทศชาติไทยทวีมีชัยชโย"""
inputs = [ThaiWordSegmentLabeller.get_input_labels(text)]
lengths = [len(text)]
def nonzero(a):
return [i for i, e in enumerate(a) if e != 0]
def split(s, indices):
return [s[i:j] for i,j in zip(indices, indices[1:]+[None])]
with tf.Session() as session:
model = tf.saved_model.loader.load(session, [tf.saved_model.tag_constants.SERVING], saved_model_path)
signature = model.signature_def[tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY]
graph = tf.get_default_graph()
g_inputs = graph.get_tensor_by_name(signature.inputs['inputs'].name)
g_lengths = graph.get_tensor_by_name(signature.inputs['lengths'].name)
g_training = graph.get_tensor_by_name(signature.inputs['training'].name)
g_outputs = graph.get_tensor_by_name(signature.outputs['outputs'].name)
y = session.run(g_outputs, feed_dict = {g_inputs: inputs, g_lengths: lengths, g_training: False})
for w in split(text, nonzero(y)): print(w, end='|')
print()
output ที่ควรจะออกทาง console ได้แก่
ประเทศ|ไทย|รวม|เลือดเนื้อชาติ|เชื้อ|ไทย| |เป็น|ประชารัฐไผท|ของ|ไทย|ทุก|ส่วน| อยู่|ดำรง|คง|ไว้|ได้|ทั้ง|มวล| |ด้วย|ไทย|ล้วนหมาย|รัก|สามัคคี| |ไทย|นี้|รัก|สงบ|แต่|ถึง|รบ|ไม่ขลาด| |เอก|ราช|จะ|ไม่|ให้|ใคร|ข่มขี่| |สละ|เลือด|ทุก|หยาด|เป็น|ชาติพลี| |เถลิง|ประเทศชาติ|ไทย|ทวีมี|ชัยชโย|
หมายเหตุ โค้ดชุดนี้ ได้มาจากตัวอย่าง predict_example.py ซึ่งอยู่ในโฟลเดอร์ thai-word-segmentation อยู่แล้วครับ
วิธีที่ 3 ใช้ cutkum
มอดูล cutkum จะใช้เทคนิคเป็น Recurrent Neural Network (RNN) โดยข้อมูลที่ใช้สอนโมเดลก็มาจาก NECTEC
ประสิทธิภาพของโมเดล
วัดในระดับตัวอักษร
- recall: 98.0% ,
- precision: 96.3%
- F-measure: 97.1%
วัดในระดับคำ
- recall: 95%
- precision:95%
- F-measure: 95.0%
วิธีติดตั้ง ก็ใช้คำสั่งนี้
pip install cutkum
มอดูลที่ต้องติดตั้งเพิ่ม
- python
- tensorflow
ถ้าเราติดตั้งมาใน 2 หัวข้อก่อนหน้านี้ ก็ไม่ต้องลงอะไรเพิ่มแล้ว
ตัวอย่างการเรียกใช้งาน
import deepcut text = """ประเทศไทยรวมเลือดเนื้อชาติเชื้อไทย เป็นประชารัฐไผทของไทยทุกส่วน อยู่ดำรงคงไว้ได้ทั้งมวล ด้วยไทยล้วนหมายรักสามัคคี ไทยนี้รักสงบแต่ถึงรบไม่ขลาด เอกราชจะไม่ให้ใครข่มขี่ สละเลือดทุกหยาดเป็นชาติพลี เถลิงประเทศชาติไทยทวีมีชัยชโย""" words = deepcut.tokenize(text) ck = Cutkum() words = ck.tokenize(text) str1 = '|'.join(str(e) for e in words) print(str1)
output ที่ควรจะออกทาง console ได้แก่
ประเทศไทย|รวม|เลือด|เนื้อชาติ|เชื้อ|ไทย| |เป็น|ประชารัฐ|ไผท|ของ|ไทย|ทุก|ส่วน| |อยู่|ดำรง|คง|ไว้|ได้|ทั้ง|มวล| |ด้วย|ไทย|ล้วนหมาย|รัก|สามัคคี| |ไทย|นี้|รัก|สงบ|แต่|ถึง|รบ|ไม่|ขลาด| |เอกราช|จะ|ไม่|ให้|ใคร|ข่มขี่| |สละ|เลือด|ทุก|หยาด|เป็น|ชาติ|พลี| |เถลิง|ประเทศชาติ|ไทย|ทวีมี|ชัยชโย
ถ้าสนใจโปรเจคนี้ก็ดาวน์โหลดได้ที่นี้
https://github.com/pucktada/cutkum
**ขอย้ำอีกที** ถ้าแสดงผลลัพธ์การทำงานตัดคำไทย ออกทางหน้าคอนโซลจอดำ จะแสดงภาษาไทยไม่ได้ ควรทิ้งผลลัพธ์ไว้ในไฟล์ หรือจะแสดงผ่านหน้าเว็บ เช่น ใช้งานผ่าน Jupyter Notebook
เปรียบเทียบการทำงานทั้ง 3 ตัว

บทความ AI อื่นๆ ที่น่าสนใจ
- วิชาเลขตอนม.ปลาย นำไปใช้ในวิชาคอมขั้นสูงอะไรบ้าง?
- ใช้ AI เขียนหนังสือเอง ซึ่งอาจถูกนำไปใช้ในทางที่ผิดได้
- เห็นหน้าคนปุ๊บก็รู้ว่าชื่ออะไร ด้วยเทคโนโลยีจดจำใบหน้า Face recognition
- ตรวจจับภาพลามก อนาจาร ด้วยความแม่นยำสูงเวอร์ ด้วย AI
- สุดล้ำใช้ AI แต่งดนตรี
- รู้จำเสียงพูด Speech Recognition ด้วย JavaScript ง่ายนิดเดียว
- ใช้ AI เล่มเกมอัตโนมัติ
- ใช้ AI ตรวจจับการเคลื่อนไหวของมนุษย์แบบเรียลไทม์
- ใช้ AI ตรวจจับใบหน้า อารมณ์คน และเพศ
- ใช้ AI แปลงภาพขาวดำเป็นภาพสี
- ใช้ AI ลบภาพพื้นหลังออก
- ตรวจจับวัตถุในรูปภาพด้วยโค้ด AI แค่ 10 บรรทัด สู่การตรวจจับวัตถุแบบเรียลไทม์ และการทำ segmentation
- สร้าง Chat bots อย่างง่ายๆ ด้วย Python
- ตัดคำภาษาไทยโดยใช้ Deep learning (AI)
- ใช้ AI เขียนโค้ดอัตโนมัติ เพียงดูภาพหน้าจอ GUI ของโปรแกรม
- วิธีเขียนโค้ดดึงข้อมูลหุ้นไทย ด้วยภาษา Python (แจกโค้ดฟรี)
- ตัวอย่างใช้ AI เนรมิตรูปภาพ
- เป็นไปได้ไหม? ที่ AI จะมาเขียนโปรแกรมแทนโปรแกรมเมอร์
เขียนโดย แอดมินโฮ โอน้อยออก
ขอบคุณมากครับ