
ไม่มีวัตถุใด รอดพ้นสายตา AI ไปได้
คำกล่าวนี้ไม่ใช่เรื่องเกินจริงปัจจุบันเราสามารถเขียน AI
เพื่อตรวจจับวัตถุในรูปภาพ (Object detection) ได้ง่ายนิดเดียว
มีตัวอย่างโค้ด ให้ลองเขียนตามมีวีดีโอ มีบทความสอนเยอะแยะเกลื่อนเนต
มีโมเดล AI ที่ถูกเทรนมาเรียบร้อยแล้ว เอามาใช้ได้เลย
มีงานวิจัย paper ตีพิมพ์ โชว์ให้เห็นกันเยอะ
รวมทั้งงานวิจัยใหม่ๆ ที่จะอัพเกรดความสามารถ AI ที่รอวันตีพิมพ์
ซึ่งตอนนี้ AI แนวนี้ก็ถูกนำไปใช้งานจริงแล้วด้วยอย่างประเทศจีนที่ได้ติดกล้อง CCTV
ทำราวกับเป็น skynet เอาไว้ตรวจจับผู้คนในท้องถนนด้วย AI
เมื่อพูดถึงอัลกอริทึม AI ที่ตรวจจับวัตถุต่างๆ ในรูป ก็มีหลายตัว เช่น
R-CNN, Fast-RCNN, Faster-RCNN, RetinaNet, SSD, YOLO เป็นต้น
การตรวจจับวัตถุในรูปภาพด้วย AI เพียงจำนวน 10 บรรทัด
อันนี้จะพามาลองเขียน AI ง่ายๆ นิดเดียว
จากบทความต้นฉบับภาษาอังกฤษ object detection ภายใน 10 บรรทัด
ตัวโค้ดจะเป็น python นะครับ เพราะงานด้านนี้ (deep learning) นิยมใช้ Python มาเป็นอันดับหนึ่ง
ภาษาอื่นอาจเสียเปรียบเยอะหน่อย ตัวอย่างมีน้อย
1) ติดตั้ง python
หาอ่านได้ตามอินเตอร์เนต ไม่ยาก หรือจะอ่านจากตำรา “วิทยาการคำนวณ” ของเด็ก ม.1 ก็ได้ มีเขียนไว้
ลิงค์ดาวน์โหลด https://www.python.org/downloads/
แต่ผมเชียร์ให้ลง anaconda ดีกว่า มันเป็นแพลตฟอร์มสำหรับงาน Data science
และเหมาะกับการงาน AI สาย machine learning และ deep learning
ที่สำคัญเหมาะกับบทความนี้ด้วยขอบอกเลย
2) ติดตั้งมอดูลพวกนี้ให้หมด อย่าตกหล่นอันใดเด็ดขาดนะครับ
pip install tensorflow==1.15.0 pip install numpy pip install scipy pip install opencv-python pip install pillow pip install matplotlib pip install h5py pip install keras==2.1.5
สุดท้ายแล้วลงมอดูล imageai ซึ่งเป็นพระเอกในการเขียน AI ตรวจจับรูปภาพ (เฉพาะบทความนี้)
pip install imageai --upgrade

แล้วต้องติดตั้ง Microsoft Visual C++ 2015-2019 ด้วยครับ
สำหรับ imageai มันเป็นไลบรารี่ Deep Learning
สำหรับงาน Computer Vision (ทำให้คอมมีวิชั่นในการมองเห็น)
ช่วยทำให้เราเขียนโค้ดไม่กี่บรรทัดก็เสร็จแล้ว
3) ดาวน์โหลดโมเดล AI ชื่อ resnet50_coco_best_v2.0.1.h5
resnet50_coco_best_v2.0.1.h5 จะถูกเทรนมาเรียบร้อยแล้ว
ขนาดไฟล์จะใหญ่หน่อย 145 MB
4) โค้ดก็ก็อปปี้ตามนี้ จากบทความต้นฉบับ
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg")) for eachObject in detections: print(eachObject["name"] , " : " , eachObject["percentage_probability"] )
หรือจะไปดาวน์โหลดโค้ดนี้ได้ที่นี้
ทริคเล็กน้อย ถ้าต้องการแสดงรูป “imagenew.jpg” ให้เด้งขึ้นมา ก็อาจเพิ่มโค้ดตรงนี้ก็ได้
from PIL import Image
image = Image.open('imagenew.jpg')
image.show()
เสร็จแล้วบันทึกไฟล์เป็นชื่อ FirstDetection.py
++++สำหรับโค้ดตัวอย่างนี้+++++
โค้ดตัวอย่างที่แสดงเขาใช้โมเดลที่เรียกว่า RetinaNet เท่านั้น
ลองเล่นดู รันได้ไม่ยาก ถ้าจะยากคงเป็นเรื่องทฤษีสำหรับผู้สนใจ
ก็หาอ่านจาก paper ต้นฉบับบโดยตรง หรือบทความออนไลน์ต่างๆ เพื่อความกระจ่าง
5) หาไฟล์รูปภาพมาทดสอบ
ในโค้ดจะระบุรูปภาพ ใช้เป็นอินพุตชื่อ “image.jpg”
ทั้งนี้ไฟล์ image.jpg
โมเดล resnet50_coco_best_v2.0.1.h5
และ FirstDetection.py
ทั้ง 3 ไฟล์จะอยู่ที่เดียวกันนะครับ

6) แล้วรันด้วยคำสั่ง
python FirstDetection.py
หรือจะรันผ่าน IDE ที่ถนัดก็ได้ครับ ไม่ต้องทำผ่านคอมมานไลน์โดยตรงแบบนี้
(วิธีรัน python ไม่ยากศึกษาได้ตามเนต หรือตามคู่มือเด็ก ม.1)
7) ผลลัพธ์จะได้ออกมาเป็นรูป imagenew.jpg
โดย AI จะตีกรอบในรูปว่ามีวัตถุอะไรได้บ้าง?
พร้อมบอกความน่าจะเป็น (เป็นตัวเลข) ว่าเป็นวัตถุอะไร
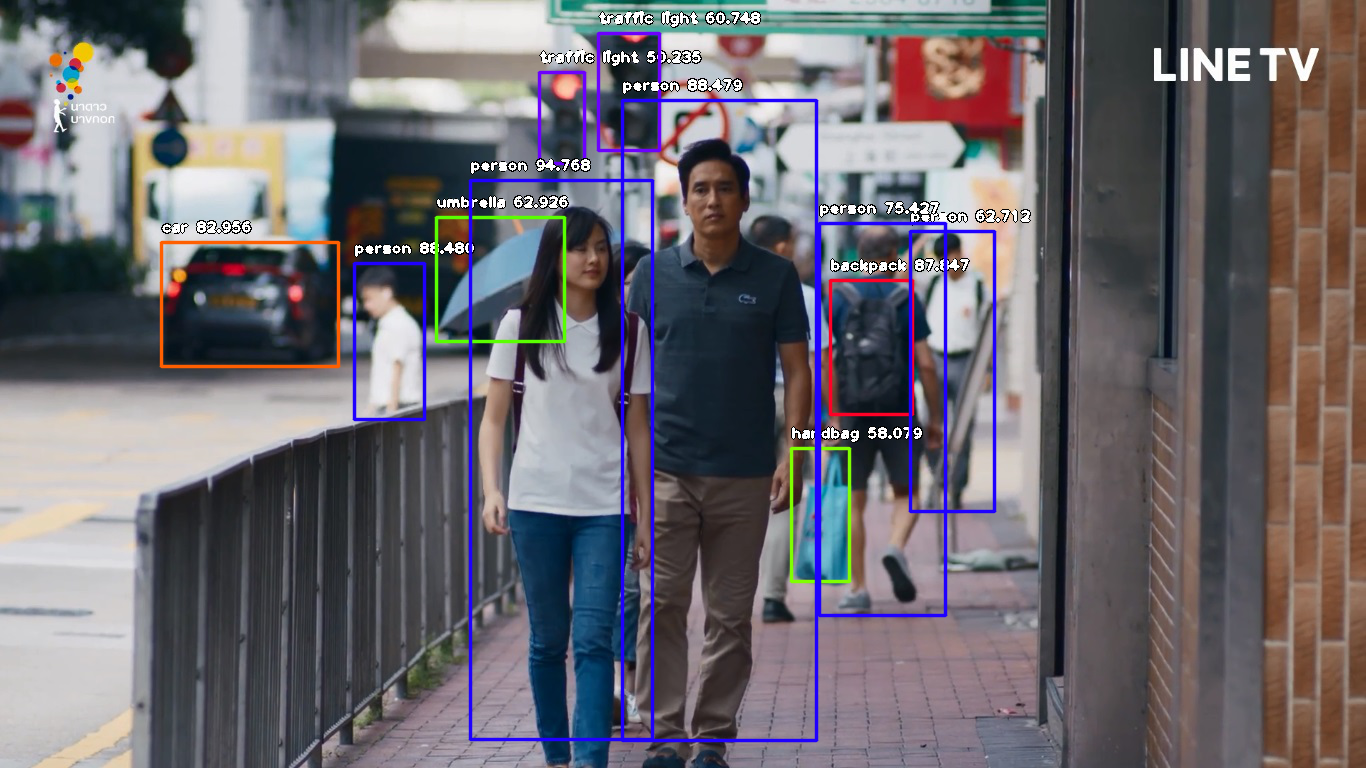
ถ้าไปดูที่คอนโซล จะบอกว่า
มันตรวจจับได้อะไรออกมา
ด้วยความน่าจะเป็นเท่าไร
(แต่ถ้ารูปขนาดใหญ่ ยิ่งเครื่องไม่แรงด้วยแล้ว ก็จะทำงานช้านะครับ)
traffic light : 50.23456811904907 traffic light : 60.74821352958679 person : 88.47966194152832 backpack : 87.8473162651062 handbag : 58.078956604003906 umbrella : 62.925803661346436 car : 82.95613527297974 person : 62.71200180053711 person : 75.42724013328552 person : 88.47867250442505 person : 94.76819634437561
.+++++++++++++++++++
สรุป จากผลลัพธ์ที่ได้
AI จะตรวจจับได้หลายสิ่ง ทั้งคน รถ กระเป๋า ไฟจราจร ร่ม ก็ทำได้
หรือจะพัฒนาต่อไปให้ตรวจับคนในรูปว่าเป็นใคร?
อย่างหลังจะเกินขอบเขตที่โค้ดทำได้
ต้องใช้อัลกอริทึมอื่นประกอบ
เช่น DeepFace ของเฟสบุ๊ค ที่ใช้ระบุตัวคนบนรูปภาพได้
การเขียนโปรแกรมตรวจจับวัตถุแบบเรียลไทม์
จากรูปภาพเดียวในหัวข้อก่อน ก็อาจพอเล่าเบื้องหลังการทำงานให้ทราบได้คร่าวๆ ดังนี้
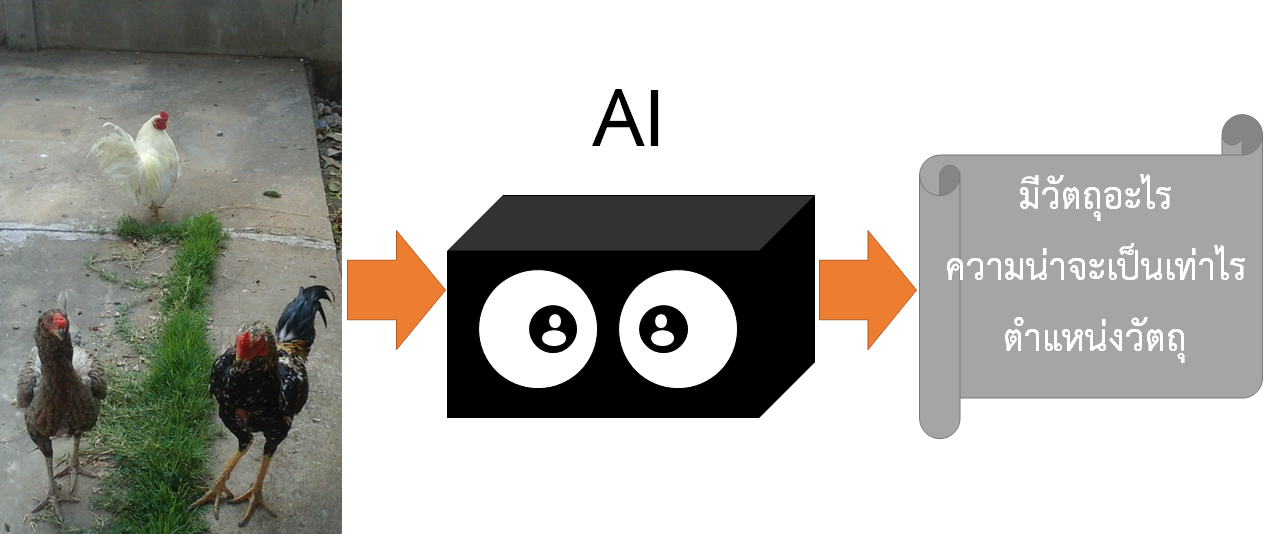
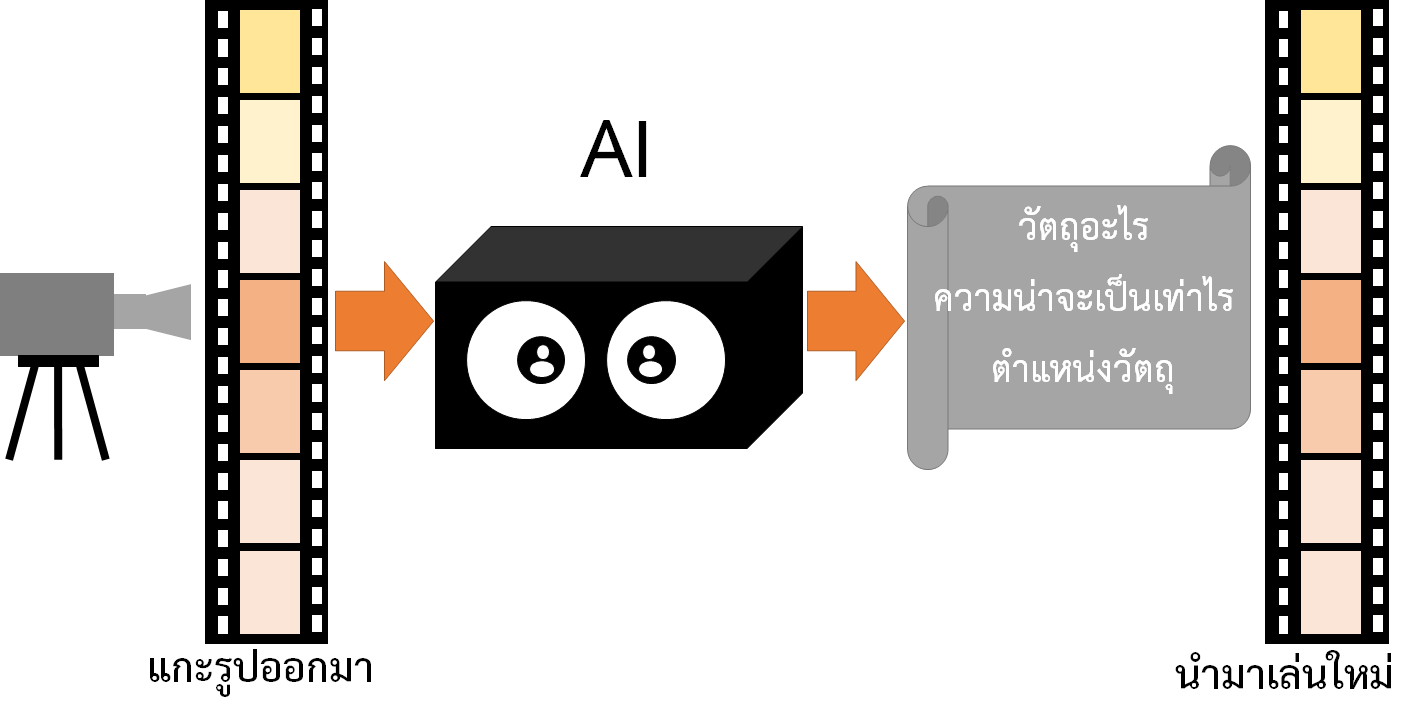
โดยจะให้คุณมองว่า AI คือกล่องดำอะไรซักอย่าง เราสนใจแค่อินพุต กับเอาท์พุตอย่างเดียว
อย่าเพิ่งไปสนใจว่าข้างในมันเป็นอะไรในตอนนี้ (มันซับซ้อนเอาเรื่อง เพราะเป็น deep learning)
เมื่อเราป้อนรูปให้ AI ใช้ไหมครับ …เดียว AI จะให้คำตอบมาว่า
- มีจำนวนวัตถุอะไรบ้าง เช่น 3 อัน 10 อัน ก็ว่ากันไป
- เป็นวัตถุอะไร ซึ่งจะให้ค่าออกมาเป็นตัวเลข เช่น เลข 1 หมายถึง ไก่ เลข 10 หมายถึง รถยนต์
- วัตถุนั้นอยู่ในตำแหน่งอะไร (boxes)
- ด้วยความน่าจะเป็นอะไร ปกตจะเป็นเลข 0-1 ถ้า 0 คือไม่ใช่เลย ถ้าเป็น 1 คือเป็นวัตถุนั้น 100%
สำหรับค่า boxes ออกเสียงว่า บ็อกๆๆๆ ไม่ใช่เสียงหมาเห่านะ แต่มันคือค่ากล่อง
โดยจะขออธิบายเพิมเติม ก็อย่างรูปที่เห็นข้างล่าง
มันเป็นตัวเลข 4 ตัว เช่น พิกัด x, y, สูง (Height) , กว้าง (Width) …ซึ่ง AI แต่ละตัวอาจไม่เหมือนกัน
ค่าพวกนี้นี่แหละ ที่จะให้เรานำไปใช้ตีกรอบล้อมวัตถุอีกที
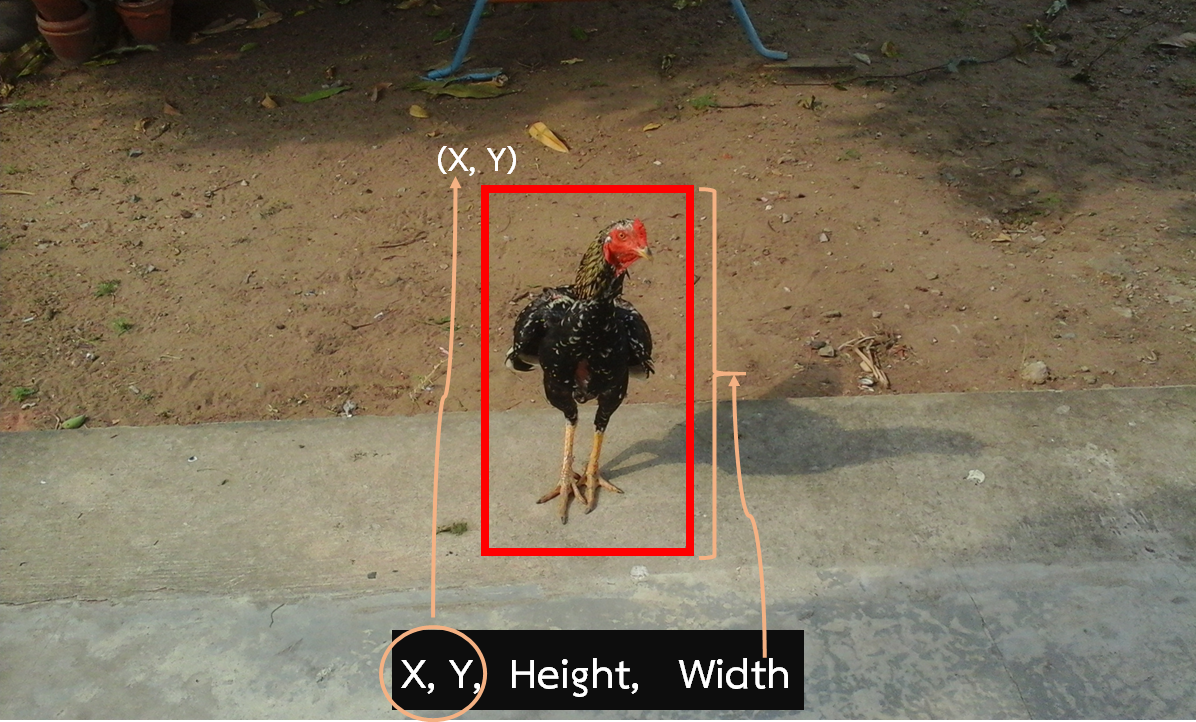
ถึงตรงนี้พอนึกภาพออกนะ ข้อมูลพวกนี้ที่เราได้จาก AI
เราจะนำมาแปลความหมาย
นำมาวาดใส่กรอบล้อมวัตถุ จะให้สีแดง สีเขียว
แล้วบอกว่าเป็นไก่ เป็นนก อะไรทำนองนี้ พอนึกภาพออกไหม
แต่ทว่าไลบรารี่ imageai ที่นำมาแสดงให้ดู มันทำให้เราแล้ว จึงซ้อนความยุ่งนี้ลงไป
คำถาม
แล้วถ้าจะตรววจับวัตถุแบบเรียลไทม์ต้องทำอย่างไร
คำตอบ ง่ายนิดเดียว จังหวะที่เราอ่านภาพจากกล้องเว็บแคม เราก็อ่านทีละรูปซิ
แล้วส่งรูปไปให้ AI ประมวล เมื่อ AI ตอบกลับ เราก็เอาข้อมูลที่ได้มาตีกรอบใส่ในรูปอีกที
แล้วนำรูปผลลัพธ์นี้ ประกอบกับคืนเป็นภาพเคลื่อนไหวต่อไป
แต่ถ้าเรามาใช้โมเดล “resnet50_coco” ข้างต้น ตรววจับวัตถุแบบเรียลไทม์ มันจะช้าครับ
เลยต้องเปลี่ยนโมเดลด่วน
ในที่นี้ผมเลือกใช้โมเดล “ssd_mobilenet_v1_coco”
เพราะทำงานได้เร็วกว่าเยอะ ทว่าความผิดพลาดยังเยอะอยู่นะครับ
แต่ถ้าเอามาเป็นกรณีศึกษา ผมว่าน่าลองเล่นนะ
ดูตัวอย่างคลิปที่ผมทำเล่นได้ครับ
เป็น AI อย่างง่ายสุด เขียนง่ายมากครับ
มันทำงานได้เร็ว ใช้ CPU ก็พอ
ต้องบอก อย่างนี้นะครับ โมเดลตรววจับวัตถุมีหลายตัวอือซ่าเลย
มีงานวิจัย มีผู้ผลิตสร้างโมเดล AI ขึ้นมาหลายตัว ดูได้ตามลิงค์ข้างล่าง
ประสิทธิภาพและข้อดีข้อเสีย ก็แตกต่างกัน
ส่วนใหญ่ก็หนีไม่พ้นเทคนิค deep learning
ถ้าใครสนใจอยากทำแบบเรียลไทม์ ก็ลองเล่นดูตามนี้ครับ เป็นภาษา python เช่นเคย
แต่ถ้าคิดจะเล่นยุ่งยากพอสมควร เพราะต้องติดตั้ง protocol-buffers และใช้งานตอนติดตั้งโปรเจค ด้วยเหตุนี้ผมจึงหาวิธีติดตั้งง่าย (นี้คิดว่าง่ายสุดแหละครับ)
การใช้โปรเจคตรวจจับวัตถุแบบเรียลไทม์
1) ติดตั้ง python
ก็ทำตามหัวข้อก่อนหน้านี้ทุกประการเลยครับ (ที่ตรวจจับวัตถุจากรูปภาพอันเดียว)
แต่มอดูลที่สำคัญและจำเป็นจริงๆ ที่ต้องติดตั้ง ก็ 2 ตัวนี้ครับ
pip install tensorflow pip install opencv-python
2) ดาวน์โหลดโค้ดเป็น zip จากโปรเจคนี้
https://github.com/am-sirdaniel/Real-Time-Object-detection-API
ดาวน์โหลดเสร็จก็แตกไฟล์ด้วยครับ
ถ้าใครใช้ git เป็น ก็ใช้คำสั่งบนคอมมานไลน์
git clone https://github.com/am-sirdaniel/Real-Time-Object-detection-API.git
เดี่ยวโค้ดของโปรเจคจะดาวน์โหลดมาอยู่ที่เครื่องเรา (อย่าลืมต่อเน็ตด้วย)
3) ถึงตรงนี้ควรเห็นโฟลเดอร์ Real-Time-Object-detection-API จากนั้นก็ cd ผ่านทางคอมมานไลน์ เข้าไป
cd Real-Time-Object-detection-API/object_detection
4) จากข้อ 3 ควรจะเห็นไฟล์ object_detection_webcam.py อยู่ในไดเรคเทอรี่
และเปิดไฟล์ object_detection_webcam.py ด้วย editor ธรรมดา เช่น notepad หรือจะเป็น IDE ก็ได้ครับ
แล้วทำการค้นหาประโยคนี้
get_ipython().run_line_magic('matplotlib', 'inline')
จากนั้นทำการคอมเมนต์ บรรทัดข้างล่างไม่ได้ใช้ครับ
(ในช่วงที่ผมเล่นโปรเจคนี้ ตัวอย่างเขาแถมบั๊กบรรทัดนี้มาฝากครับ เลยต้องเอาออก)
#get_ipython().run_line_magic('matplotlib', 'inline')
5)รันคำสั่งต่อไปนี้ เดี่ยวกล้องเว็บแคมในคอมเรา ก็จะเปิดขึ้นมาเอง จากนั้น AI ก็ดักจับทุกสิ่งอย่างให้เรา
python object_detection_webcam.py
หรือจะรันผ่าน IDE ที่ถนัดก็ได้ครับ ไม่ต้องทำผ่านคอมมานไลน์โดยตรงแบบนี้
หมายเหตุ เราสามารถปรับขนาดหน้าจอเว็บแคมที่โชว์ได้
โดยเข้าไปหาโค้ดชุดนี้
cv2.imshow('image',cv2.resize(image_np,(1280,960)))
แล้วปรับขนาดหน้าจอเว็บแคม อย่างของผมปรับเป็นขนาด 640 x 480 ก็เข้าไปแก้โค้ดตามนี้
cv2.imshow('image',cv2.resize(image_np,(640,480)))
การใช้โปรเจคตรวจจับวัตถุแบบเรียลไทม์ อีกทางเลือกหนึ่ง
ในหัวข้อนี้จะกล่าวถึงการใช้โปรเจคตรวจจับวัตถุแบบเรียลไทม์อีกเวอร์ชั่น(เป็นทางเลือก) อันนี้จะเป็นตัวต้นฉบับจริง ซึ่งยุ่งยากกว่าก่อนหน้านี้ (ติดตั้งบน linux)
วิธีการติดตั้งโปรเจค
1) ติดตั้ง python
ก็ทำตามหัวข้อก่อนหน้านี้ทุกประการเลยครับ (ที่ตรวจจับวัตถุจากรูปภาพอันเดียว)
แต่มอดูลที่สำคัญและจำเป็นจริงๆ ที่ต้องติดตั้ง ก็ 2 ตัวนี้ครับ
pip install tensorflow pip install opencv-python
2) ดาวน์โหลดโค้ดเป็น zip จากโปรเจคนี้
https://github.com/tensorflow/models
ดาวน์โหลดเสร็จก็แตกไฟล์ด้วยครับ
ถ้าใครใช้ git เป็น ก็ใช้คำสั่งบนคอมมานไลน์
git clone https://github.com/tensorflow/models.git
เดี่ยวโค้ดของโปรเจคจะดาวน์โหลดมาอยู่ที่เครื่องเรา (อย่าลืมต่อเน็ตด้วย) ซึ่งควรจะเห็นโฟลเดอร์ models นะ
3) ดาวน์โหลด protobuf
https://github.com/google/protobuf/releases/download/v3.0.0/protoc-3.0.0-linux-x86_64.zip
แตก zip ไปที่ bin
unzip -o protobuf.zip
ซึ่งจากนี้ควรจะใช้คำสั่ง protoc ได้
4) ให้ cd ไปที่โฟลเดอร์ models/research/ ของโปรเจค แล้วรันคำสั่ง
protoc object_detection/protos/*.proto --python_out=.
เมื่อดูในโฟลเดอร์ models/research/object_detection/protos ควรจะเห็นไฟล์ .py ต่างๆ ถูกสร้างขึ้นมา
5) เวลาจะใช้งานก็ให้ไปที่โฟลเดอร์ models/research/object_detection
ซึ่งจะเห็นไฟล์ตัวอย่าง object_detection_tutorial.ipynb
การเปลี่ยนโมเดล AI
สำหรับโมเดล AI ที่ดักจับวัตถุแบบเรียลไทม์ผ่านกล้องเว็บแคม
จากโค้ดตัวอย่างที่สาธิต เขาจะใช้โมเดลที่ชื่อ “ssd_mobilenet_v1_coco”
ถ้าค้นหาในโค้ดควรเห็นบรรทัดนี้ครับ
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
ซึ่งมันจะทำงานเร็ว บน CPU ก็ทำได้สบายๆ (แต่เครื่องควรแรงจะดีมากครับ)
แล้วถ้าต้องการเปลี่ยนโมเดล AI ก็ลองเข้าไปดูที่ลิงนี้ detection model zoo ตามที่กล่าวมาข้างต้น ก็จะเห็นตารางตามรูปข้างล่าง
ซึ่งวิธีเลือก AI ให้ดูว่ามันบอกสปีดความเร็วตอนทำงานว่าช้าหรือเร็วเท่าไร (หน่วยเป็น ms)
พร้อมดูค่า COCO mAP เพื่อเปรียบเทียบ ถ้าค่านี้สูงแสดงว่าทำงานดีเยี่ยมมากกว่า
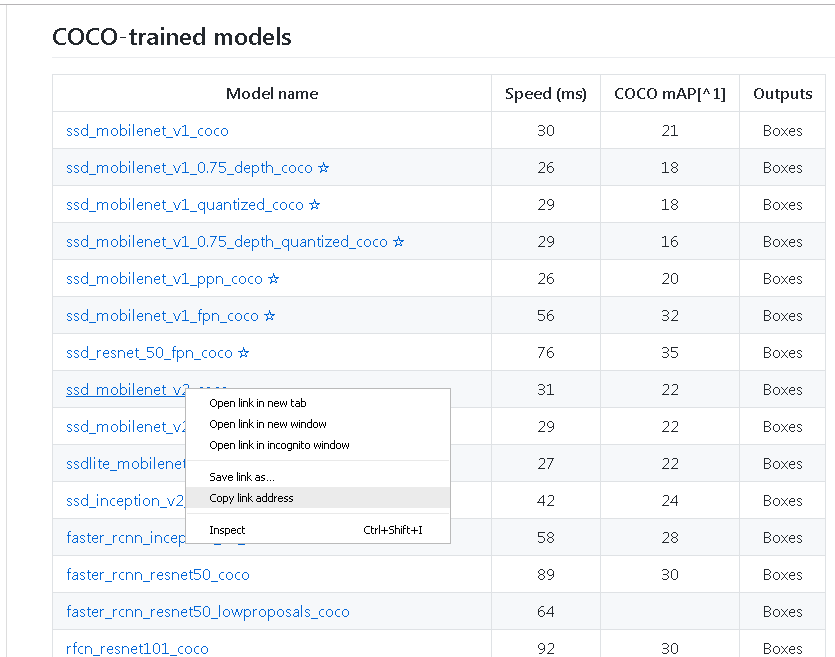
อย่างของผม ลองเปลี่ยนไปใช้โมเดลชื่อ “ssd_mobilenet_v2_coco” โดยคลิก Copy link address ก็จะเห็น url
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz
ผมแค่ตัดเหลือคำว่า ssd_mobilenet_v2_coco_2018_03_29 แล้วเอาไปแปะแก้ไขในโค้ด
MODEL_NAME = 'ssd_mobilenet_v2_coco_2018_03_29'
จากนั้นก็รันโค้ด python object_detection_webcam.py อีกครั้งหนึ่ง
สำหรับขั้นตอนนี้อย่าลืมต่อเนตด้วยนะ เพราะโค้ดจะไปดาวน์โหลดโมเดล AI จากข้างนอกเข้ามาครับ
- สังเกตให้ดีควรเห็นไฟล์ ssd_mobilenet_v2_coco_2018_03_29.tar.gz
- พร้อมทั้งโฟลเดอร์ ssd_mobilenet_v2_coco_2018_03_29 ซึ่งถูกแตกออกมาโดยอัตโนมัติ
โดยไฟล์ทั้งหมดจะอยู่ใต้โฟลเดอร์ Real-Time-Object-detection-API/object_detection อีกที
หรือ models/research/object_detection
จากนั้นก็ลองเล่นผ่านกล้องเว็บแคมดูได้เลย
*** แต่ทั้งนี้ใช้ว่าจะทำได้ทุกโมเดลที่กล่าวมานะครับ บางอันก็ทำไม่ได้
การทำ Segmentation
จากที่เล่ามาข้างต้น Object detection สามารถระบุตำแหน่งของวัตถุด้วยการใส่ box ตีกรอบล้อมวัตถุ
แต่โมเดล AI บางตัวสามารถให้ค่าตัวเลขเป็น masks เพิ่มเติมนอกจากตัวเลขค่า boxes
โดย mask จะเป็นชุดตัวเลขที่จะนำไปไฮไฮท์วัตถุนั้นๆ ในรูปได้ ดังที่เห็นในรูปข้างล่าง

ค่า mask ประโยชน์เอาไว้ทำเรื่อง Segmentation เพื่อแยกวัตถุในรูปออกจากรูปหลักได้
ประโยชน์เช่น เอาไว้ลบรูป background ออกไป

แนวคิดเรื่อง mask
จะขอยกรูปภาพข้างล่าง ที่เป็นสีน้ำเงิน

ซึ่งปกติภาพๆ ภาพหนึ่งจะประกอบด้วยพิกเซล (จุดสี)
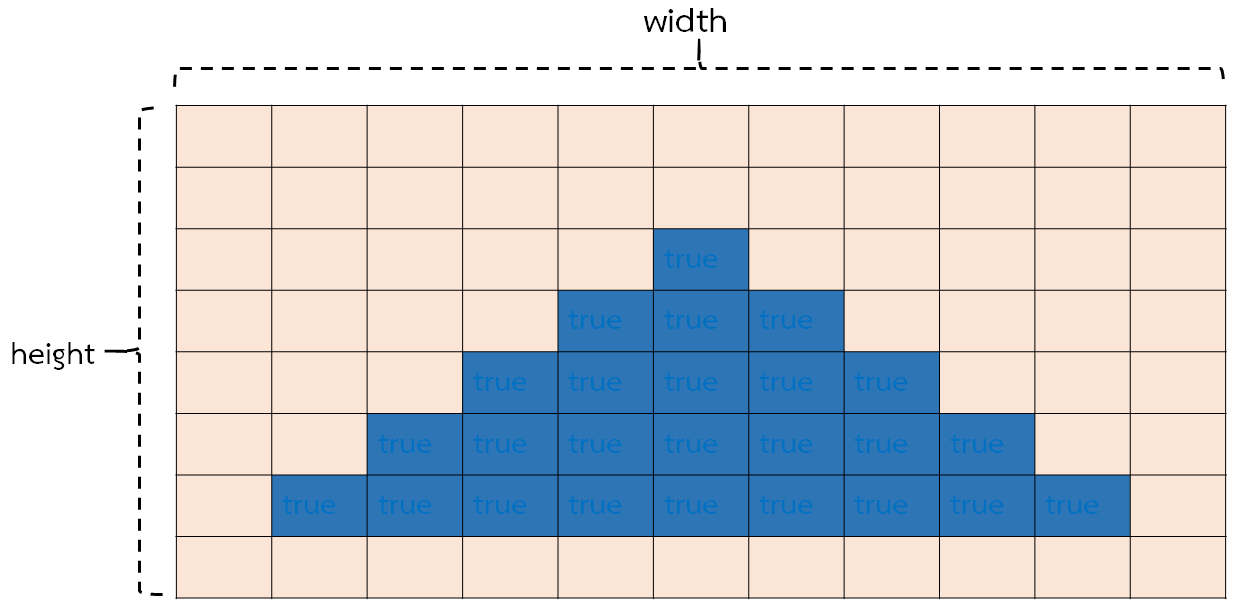
สำหรับ mask มันก็คือ หน้ากากที่มีความกว้าง x สูง เท่ากับรูปภาพ เพียงแต่จุดพิกเซลของ mask จะระบุค่า true เมื่อจุดนั้นตรงกับรูปภาพต้นฉบับ ถ้าไม่ใช่จะระบุเป็น false
ซึ่ง true กับ false จะใช้เป็นค่าอย่างอื่นก็ได้เช่น 1,0 เป็นต้น

วิธีการเขียนโค้ดไม่ยาก (ค้างไว้เดี่ยวมาเขียนต่อ เลยให้ดูคลิปตัวอย่างการทำงานพลางๆ ก่อน)
สรุปในมุมโปรแกรมเมอร์
ถามว่าเขียนยากไม่ ก็ตอบไม่ยากเท่าไร
เพราะโมเดล AI พวกนี้ถูกเทรนออกมาเรียบร้อยแล้ว
เราแค่รู้จักส่งค่าอินพุต และนำเอาท์พุตที่ได้มาแปลความหมายอีกที
จะตีกรอบล้อมรูปภาพ บอกว่าเป็นอะไร
หรือจะประยุกต์ทำอย่างอื่นก็ได้เยอะครับ
แล้วแต่จะพลิกแพลง แล้วแต่ไอเดียเราครับ
(ความยากคือตอนสร้างและสอนให้ AI ฉลาด)
ถึงจะบอกว่าเขียนโปรแกรมไม่ยากก็จริง
แต่ก็อาจยุ่งยากสักหน่อย
เพราะส่วนใหญ่เป็น python เยอะเชียว
ภาษาอื่นอาจเสียเปรียบหน่อย
แต่อนาคตก็ไม่แน่
อาจจะมี API ที่ทำงานง่ายกว่านี้ก็เป็นได้
และก็ไม่ขึ้นอยู่กับภาษาเขียนโปรแกรมอีกด้วย
ขอให้โชคดีครับ กับโลกยุค AI
เรียนรู้ไว้ไม่เสียหาย เพราะเราคงปฏิเสธมันไม่ได้
ยิ่ง AI มีเขียนไว้ในยุทธศาสตร์ 20 ปี ของบ้านเรา เชียวน๊า
เครดิต
- รูป ละครเลือดข้นคนจางขอบคุณ
- บทความต้นฉบับ https://towardsdatascience.com/object-detection-with-10-lines-of-code-d6cb4d86f606
- ขอบคุณไลบรารี่ ImageAI https://github.com/OlafenwaMoses/ImageAI
- ติวเตอร์พร้อมโค้ด https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
- ติวเตอร์พร้อมโค้ด https://github.com/am-sirdaniel/Real-Time-Object-detection-API
- model zoo
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
เขียนโดยแอดมินโฮ โอน้อยออก