ในแง่ของการสร้างซอฟต์แวร์ฝั่ง Front-end เมื่อพูดการออกแบบภาพหน้าจอ GUI ของโปรแกรม ปกติจะมีทีมกราฟฟิกดีไซน์เป็นคนออกแบบให้ … แล้วโยนงานมาให้พวกเราชาวโปรแกรมเมอร์ เพื่อแปลงภาพเป็นโค้ดของซอฟต์แวร์ หรือเว็บไซต์ หรือโมบายแอพ อะไรประมาณนี้ (หรือเราจะเป็นมนุษย์ all in one ก็ได้นะ อะไรก็ตูทำคนเดียวหมดเลย)
และจากข่าวที่ AlphaGoจักรกลอัจฉริยะของ Google เอาชนะแชมป์โลกโกะ อย่างคุณ Ke Jie ในปี 2560 (ปีที่แล้วก็ชนะ Lee Sedol ปี 2559 ) ก็ตอกย้ำขีดความสามารถของ AI ที่นับวันเก่งกล้าขึ้น

ถ้าถามว่า เป็นไปได้ไหมที่จะนำ AI มาเขียนโค้ด เพียงแค่ดูภาพ GUI (Graphical user interface) ของหน้าจอโปรแกรม แล้วเสกปุ๊บกลายเป็นซอร์สโค้ดได้เลย
คำตอบ ก็น่าจะใช้ AI หรือชื่อเต็ม Adobe Illustrator มาเขียนโค้ดอัตโนมัติให้เราได้ …เอ้หรือ ทำไม่ได้ดีล่ะ
เฮยเดี่ยวก่อนนะ ปัญญาประดิษฐ์นะเฟ้ย ไม่ใช่ Adobe illustrator ชื่อย่อเหมือนกัน แต่คนละความหมาย
มันต้อง AI ประมาณดังรูปข้างล่าง

จะใช้คนเหล็ก อาร์โนลด์ เขียนโค้ดก็โหดสาดเลือดกระเด็น หน้าตา AI ควรสะสวยประมาณนี้ เอาไว้ช่วยเขียนโค้ดดีกว่า ว่าไหมครัช!

มาๆ ขอวกกลับเข้าเรื่องดีกว่า หลังจากพาออกทะเล (โทดทีน้า อิๆๆๆ)
ต้องบอกว่ามีงานวิจัยของคุณ Tony Beltramelli (22 พฤษภาคม 2017) เขาได้เสนอวิธีการใหม่ให้ AI ช่วยเขียนโค้ดให้ วิธีนี้ตั้งชื่อว่า pix2Code สันนิษฐานว่าคงมาจากชื่อเต็ม Pixel to source code เพราะมันเอาจุด Pixel จากรูปภาพ GUI ของหน้าจอโปรแกรม มาใช้เป็น Input ส่งไปให้ AI ทำการอ่านแล้วเขียนโค้ดขึ้นมาอย่างอัตโนมัติ สบายปรื๋อ!!!! [1]
ใครสนใจดูวีดีโอสาธิตการใช้เทคนิคนี้ ก็ดูได้ที่ลิงค์นะครับ จะเห็นว่าแค่วาดรูปหน้าจอ แล้วก็รัน AI ให้สร้างโค้ดออกมาได้เลย (ในตัวอย่างแสดงเฉพาะโค้ดบน iOS กับตัวอย่างสร้างเป็นไฟล์ HTML)
จากการดูคลิป
หลายคนอาจอุทานในใจ “พระเจ้าจอร์จ มันยอดมากเลยนะซาร่า AF”
หรืออาจอุทาน “อ้าวเฮย ซวยแล้วไง! โปรแกรมเมอร์ฝั่ง Front-end ทำไงดีฟ่ะ ตูจะตกงานมั๊ยเนี่ย!”
ในทางเทคนิคโดยย่อของงานวิจัยชิ้นนี้สรุปได้ว่า
ด้วยเทคนิค pix2Code จะใช้เคล็ดวิชา AI ที่ชื่อว่า Deep learning ซึ่งก็คือ Neural network (เครือข่ายประสาทเทียม) แต่เป็นระดับขั้น Advanced กว่าเดิม ซึ่งเบื้องหลังได้มีการใช้ Neural network 2 ประเภทมาผสมผสานกัน ได้แก่ CNN กับ LSTM
ด้วยวิธีนี้ เราสามารถสร้างโค้ด จากไฟล์รูปภาพ GUI ของหน้าจอโปรแกรมเพียงภาพเดียว โดยโค้ดที่ถูกสร้างขึ้นมานั้น สามารถสร้างได้ 3 แพลท์ฟอร์มหลักๆ ได้แก่ iOS, Android และเว็บ (HTML/CSS)
จากงานวิจัยสร้างโค้ดได้ไม่แม่นเท่าไรแฮะ ยังให้ความถูกต้องแค่ 77% เย้โปรแกรมเมอร์ฝั่ง Front-end ยังไม่ตกงานง่ายๆ เว้ยเฮย (อันนี้ความเห็นส่วนตัวที่ได้จากการอ่านวิจัย ผมว่าอีกนานกว่าจะสำเร็จอยู่นะ)
สำหรับหน้าเพจอย่างเป็นทางการของโปรเจคนี้ อยู่ที่ https://uizard.io/ เขาเรียกตัวเองว่า UIzard (pix2Code คือชื่อเทคนิคสร้างโค้ดอัตโนมัติด้วย AI)
ซึ่งเป้าหมายของ UIzard ได้แก่ โค้ดดิ่งน้อยลด ทำซ้ำได้มากขึ้น เกิดนวัตกรรมใหม่
ส่วน Mission: Impossible ของโครงการนี้คือ ตือ ตื่อ ตือ ตื่อ ตือ ตื้อ ตื๊อ ตื่อ ตื้อ ตือ ตื่อ ตื้อ

เฮยอันนั้นมันรูป Mission ของตัวหนังอะนะ เอามาผิดครับ สำหรับ Mission ที่โปรเจคนี้ต้องการคือ
เป้าหมายของเราคือ ช่วยให้ผู้คนจำนวนมากสามารถสร้างโซลูชันของซอฟต์แวร์ได้ โดยลดระยะเวลาการสร้างให้สั้นลง จากไอเดียเริ่มต้นไปสู่ระบบที่ทำงานได้อย่างสมบูรณ์แบบ เพียงแค่คลิกปุ่มสร้างเท่านั้น โดยทั้งนี้ UIzard จะเปลี่ยนไอเดียของคุณให้กลายเป็นซอร์สโค้ดที่ทำงานได้ บนทุกแพลตฟอร์มตามที่คุณตั้งใจไว้
ขอย้ำ เรื่องการสร้างโค้ดอัตโนมัติไม่ใช่เรื่องใหม่ มนุษย์โลกคิดค้นวิธีสร้างกันมานานแล้ว
- อย่างงานของ Kory Becker เขาใช้ AI (genetic algorithm) เขียนโค้ดภาษา Brainfuck อัตโนมัติ
- หรือทีมวิจัยของไมโครซอฟต์ ที่มุ่งมั่นพัฒนา AI มาใช้เขียนโค้ดอัตโนมัติ เพื่อให้คนที่ไม่รู้เรื่องโปรแกรม สามารถเขียนได้ ขอเพียงมีไอเดียในหัวก็พอ ยิ่งเป็น AI มาจากบริษัทยักษ์ใหญ่ไอที อย่างไมโครซอฟต์ด้วย ก็น่าสนใจมาก นี้คือตัวอย่างงานวิจัย DEEPCODER: LEARNING TO WRITE PROGRAMS อันนี้ใช้ AI เขียนโปรแกรม จากการเรียนรู้โค้ดชาวบ้านเขา (ถ้ามีโอกาสคงได้เล่า)
สำหรับบทความนี้ขอกล่าวถึงเทคนิค pix2Code อย่างเดียว เพราะมันใช้เทคนิคใหม่ๆ อย่าง Deep learning ที่เป็นกระแสในปัจจุบัน ดูแล้วมีอนาคต มีความเป็นไปได้สูง (อีกอย่างผู้เขียนก็เข้าใจด้วย 555)
ดูสรุปเนื้อหาตามคลิปนี้ที่ผมทำนะครับ
ส่วนเนื้อหาต่อจากนี้ไปเป็นเรื่องเทคนิคล้วนๆ
ถ้าใครไม่สนใจ ไม่จำเป็นต้องอ่านก็ได้ ตัดจบเลย
คอนเซปต์ pix2Code
แนวคิด pix2Code ให้ลองนึกว่ามีรูปภาพหนึ่ง ถ้าเป็นหัวสมองมนุษย์เห็นภาพปุ๊บ ก็สามารถบรรยายได้ว่าคืออะไร ใช่ไหมครับ!
|
|
|
 |

(รูปข้างบน ควรเปิดดูบนคอมจะดีกว่าครับ)
แต่ถ้าเปลี่ยนเป็น AI ให้มาดูรูปภาพแทนล่ะ
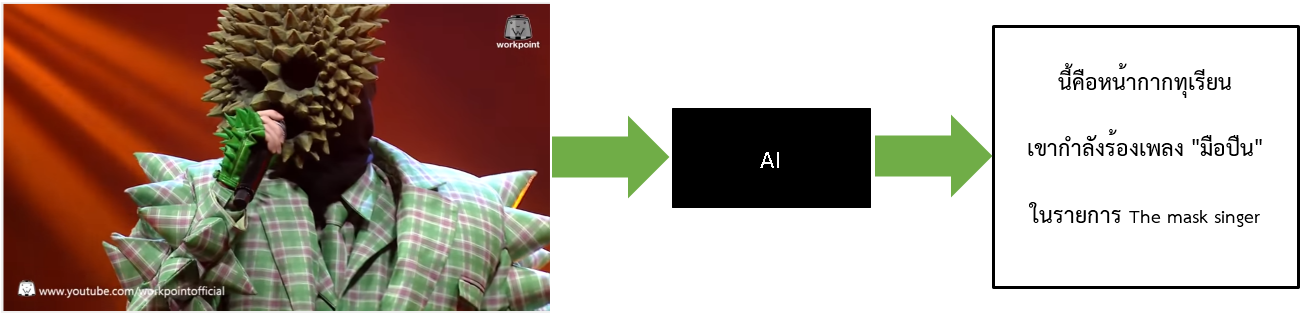
จากรูปข้างบน ถ้าเราใช้ AI ซึ่งเป็นกล่องสีดำ รับ input เข้ามาเป็นรูปหน้ากากทุเรียน (ในรายการ The mask signer) แล้วบรรยายเป็นคำพูดออกมา
คำตอบ ทำได้ เพราะตอนนี้มี AI ของ Google ที่อ่านรูปภาพ แล้วเขียนคำอธิบายรูปนั้นได้ (captions)
แล้วถามต่อ ถ้าเปลี่ยนจากรูปภาพข้างบน ให้มาอ่านหน้าจอ GUI ของโปรแกรมแทน แล้วบรรยายออกมาเป็นโค้ดโปรแกรมมิ่ง ทำได้ไหมล่ะ?
คำตอบ มีความเป็นไปได้นะ ดังรูปข้างล่าง
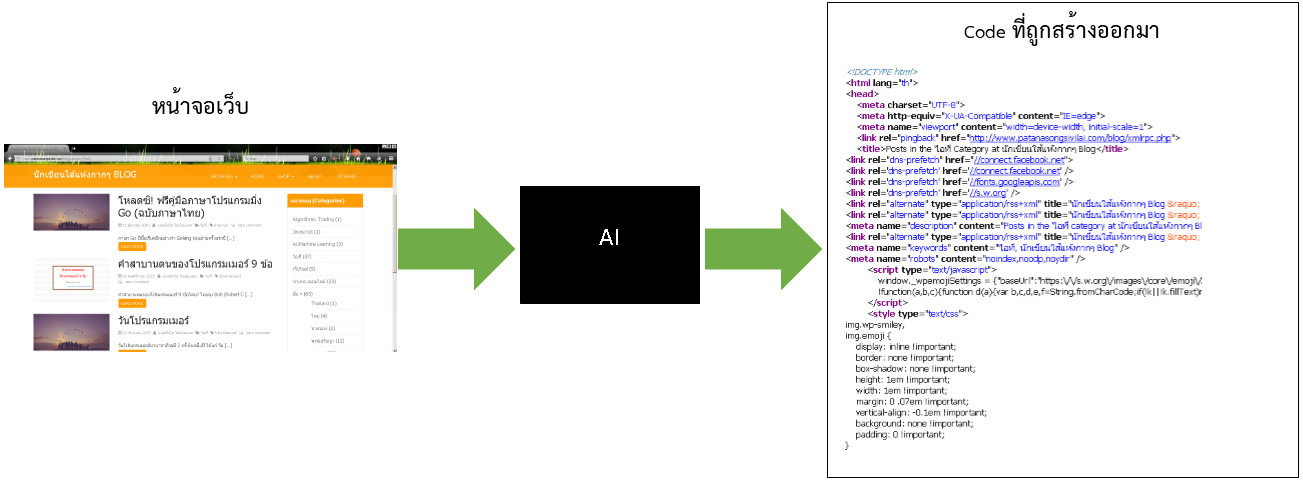
จากรูปข้างบน คือแนวคิดที่ pix2Code คิดจะทำ ขอแค่เห็นหน้าจอ GUI ก็สร้างโค้ดออกมาได้
ก่อนที่จะเข้าใจงานวิจัย ต้องเข้าใจ 4 อย่างดังนี้
- ภาษา DSL
- One-hot encoding
- CNN
- LSTM
เดี่ยวจะอธิบายเรื่องเหล่านี้ ที่ละหัวข้อ (ถ้าอธิบายไม่เข้าใจอย่างด่ากันนะครับอิๆๆๆ)
ภาษา DSL
ภาษา DSL ชื่อเต็มคือ domain-specific language ซึ่งตอนแรกผมก็งงกับมัน คืออะไรหว้า 555
อย่าอ่านผิดเป็น DSI ไม่ใช่กรมสอบสวนคดีพิเศษ นะครัช
ตามความเข้าใจของผม ภาษา DSL จะหมายถึงภาษาโปรแกรมอะไรก็ได้ ที่ใช้ในขอบเขตงานที่เฉพาะเจาะจง (domain เฉพาะอย่าง) ซึ่งในงานวิจัยแนวสร้างโค้ดอัตโนมัติ เขาจะนิยมใช้ภาษา DSL กันคร๊าบบบบ
ยกตัวอย่างภาษาที่เป็น DSL
- ภาษา SQL -> ใช้งานติดต่อฐานข้อมูล
- ภาษา HTML -> ใช้งานสร้างหน้าตาเว็บ
- ภาษา CSS -> ใช้ตกแต่งหน้าเว็บให้สวยงาม
- และอื่นๆ
จะเห็นว่าภาษาที่ยกตัวอย่างมา ใช้ได้เฉพาะเจาะจงในงานนั้นๆ เอาไปใช้อย่างอื่นไม่ได้ เช่น ภาษา SQL จะกระโดดข้ามไปไว้สร้างหน้าตาเว็บไม่ได้ ภาษา CSS จะเอาไปใช้ติดต่อฐานข้อมูลไม่ได้ เป็นต้น
จะไม่เหมือนภาษา Java, C, C++ ที่ใช้งานได้ทั่วไป ตั้งแต่สากเบือยันเรือรบ ซึ่งอันนี้ไม่เรียกว่า DSL
สำหรับงานชิ้นนี้ คุณ Tony Beltramelli ออกแบบภาษา DSL อย่างง่ายๆ เพื่ออธิบายหน้าจอว่ามี layout ของโปรแกรมเป็นอย่างไรเสียมากกว่า ไม่ได้ระบุว่าหน้าจอมีข้อความอะไรบ้าง (ไม่สนใจ text บนจอเลย) เรียกว่ายังไม่เฟอร์เฟกเท่าไรเนอะ
สาเหตุที่ออกแบบง่าย เพื่อลดปริมาณ tokens ในโค้ด ไม่ให้มากเกินไป (ลดปริมาณคลังศัพท์ไม่ให้มีเยอะ ขืนมี tokens เยอะในโค้ด การทดลองจะยุ่งยากไปอีก แถมเปลืองหน่วยความจำด้วย)
จากการอ่าน paper ผมเข้าใจว่า จำนวนคำศัพท์ในภาษา DSL ที่คุณ Tony Beltramelli ออกแบบมีจำนวนจำกัดแค่ 512 tokens
***ความรู้เพิ่มเติม คำว่า token ในภาษาโปรแกรมมิ่ง จะประกอบไปด้วย 5 ประเภท ได้แก่ Reserved words, Operators, Identifiers, Constants, Separators
ลองมาดูตัวอย่างภาษา DSL ที่เขาออกแบบกันเถอะ
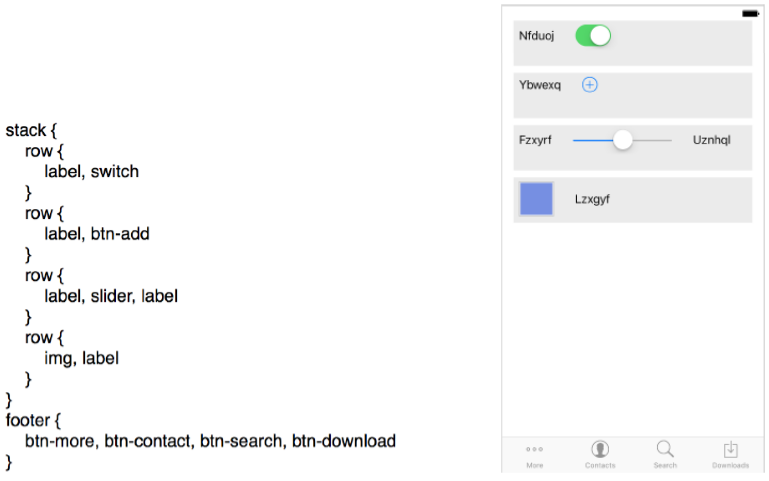
เมื่อมองโค้ดดังกล่าวให้เป็นลำดับของ tokens ก็จะได้ดังตัวอย่างข้างล่าง
![]()
ซึ่งสาเหตุที่ให้มองเป็นลำดับ เนื่องจาก AI ของงานชิ้นนี้ มองเห็น tokens เป็นแถวเรียง ไม่ใช่เห็นเป็นกระดาษ A4
ถึงตอนนี้หลายคนอาจสงสัย ถ้าผมใช้ AI ของเขาแล้ว อย่างนี้ผม/หนูต้องเรียนรู้ภาษา DSL ที่เขาดีไซน์อะดิ
คำตอบ มันไม่ต้องจ้า! เพราะ DSL เป็นภาษาที่ AI สร้างออกมาตอนเริ่มต้น (จะได้สะดวกต่องานวิจัยด้วย) สุดท้ายแล้ว DSL จะถูกแปลงเป็นภาษาโปรแกรมมิ่งธรรมดาบน Android, iOS และ HTML/CSS รวดเดียวทีหลัง
ทำความรู้จัก one-hot encoding
one-hot encoding มันคือการเข้ารหัสข้อมูลให้เป็น binary (0 กับ 1) ลองมาดูตัวอย่างการเข้ารหัส token ในภาษา DSL ดังนี้
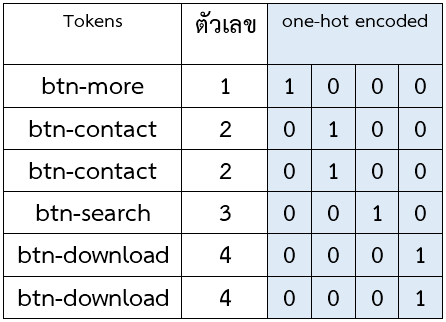
ตารางข้างบน คอลัมน์ขวาสุดสีฟ้าเป็นแค่ภาพตัวอย่างการเข้ารหัส tokens แล้วได้เป็นอาร์เรย์ที่มีบิตเป็น 1 แค่อันเดียว บิตที่เหลือเป็น 0 หมด
เราต้องเข้าใจว่า AI มันคือคอมพิวเตอร์ มันไม่ใช่คนใช่ไหมล่ะ มันอ่าน tokens ที่เป็นตัวหนังสือไม่ออกอะนะ ดังนั้นจึงต้องแปลงเป็นตัวเลขเช่น 150, 1.9 , 8.77, 0.55 อะไรก็ว่าไป
แต่ในงานวิจัย เลือกวิธีเข้ารหัสเป็น one-hot encoding ซึ่งง่ายและนิยมกัน แต่ข้อเสียเข้ารหัสด้วยวิธีนี้คือ ยิ่งมี tokens เยอะ (จำนวนคลังศัพท์เยอะ) จะเปลืองหน่วยความจำมาก
(ถ้าเป็นไปได้งานวิจัยแนะนำให้เข้ารหัส tokens ด้วย word2Vec ดีกว่า ซึ่งคำว่า word2Vec ก็คือการแปลงคำศัพท์ ให้อยู่ในรูป vectorทางคณิตศาสตร์)
โครงสร้างของ pix2Code
จากรูปข้างล่างให้มองกล่องสีเทาคือ pix2Code
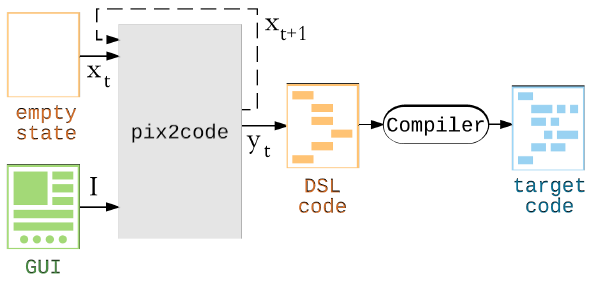
- ก้อน input ที่เขียนว่า empty state อันนี้คือก้อนของ tokens ซึ่งเข้าไปในกล่องสีเทา ทีละ 48 อัน
- ก้อน input ที่เขียนว่า GUI มันคือภาพ GUI ของหน้าจอโปรแกรม ที่มีอันเดียว
- ส่วนกล่อง pix2Code ต่อไปเรียกว่า กล่องสีเทา แล้วกันเนอะ …เพื่อความสะดวก
คราวนี้จะฉาย x-rays ให้เห็นว่ากล่องสีเทาที่ว่านี้ ข้างในประกอบด้วยอะไรบ้าง
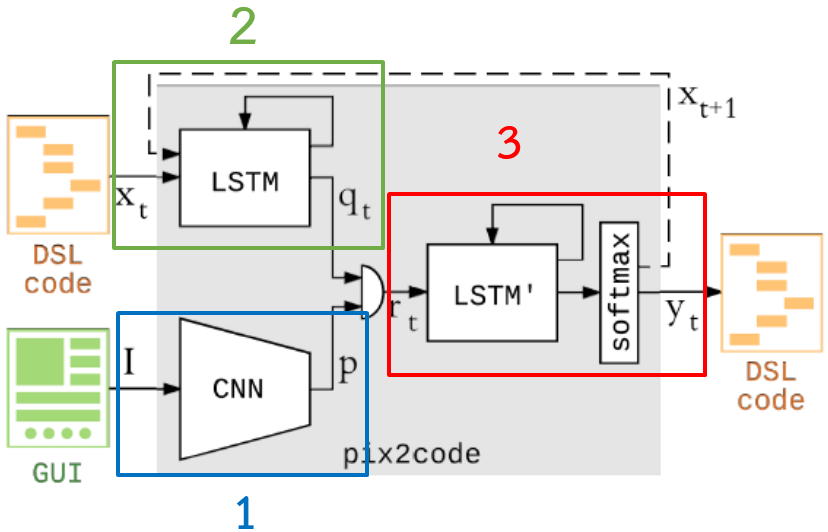
- ในกรอบสีน้ำเงินหมายเลข 1 งานวิจัยเรียกว่า Vision Model ใช้จัดการเรื่องรูปภาพ โดยจะใช้โมเดล Neural Network ประเภท CNN
- ในกรอบสีน้ำเงินหมายเลข 2 งานวิจัยเรียกว่า Language Model ใช้จัดการเรื่องภาษา โดยจะใช้โมเดล Neural Network ประเภท LSTM
- ในกรอบสีน้ำเงินหมายเลข 3 จะเป็น โมเดลรวมข้อมูล จะเอา output จากโมเดลข้อ 1 กับ 3 มารวมกัน แล้วได้ผลลัพธ์สุดท้ายเป็น token ในภาษา DSL (สิ่งที่ pix2Code ทำนายออกมา)
โดยโมเดลในแต่ละหัวข้อ ผมก็จะอธิบายรายละเอียดเพิ่มนะครับ
Vision Model
ไส้ในของ pix2Code ก้อนเบอร์ 1 (รูปก้อนหน้านี้) จะใช้โมเดลที่ชื่อ Vision Model มาอ่านรูปภาพหน้าจอ GUI โดยเบื้องหลังมันเป็น Neural Network ประเภท CNN หรือก็คือสำนักข่าวชื่อดัง ของอเมริกา ที่ไม่มีใครไม่รู้จักนั้นเอง

อ้าวผิดๆ ไม่ใช่ CNN สำนักข่าวต่างประเทศ
CNN ในที่นี้คือ Convolutional Neural Network มันเก่งในงานประเภท Computer vision ก็พวกงานประมวลผลรูปภาพนั้นแหละ
ก่อนอื่นลองมาดูตัวอย่างการใช้ CNN จำแจกรูป ดังตัวอย่าง
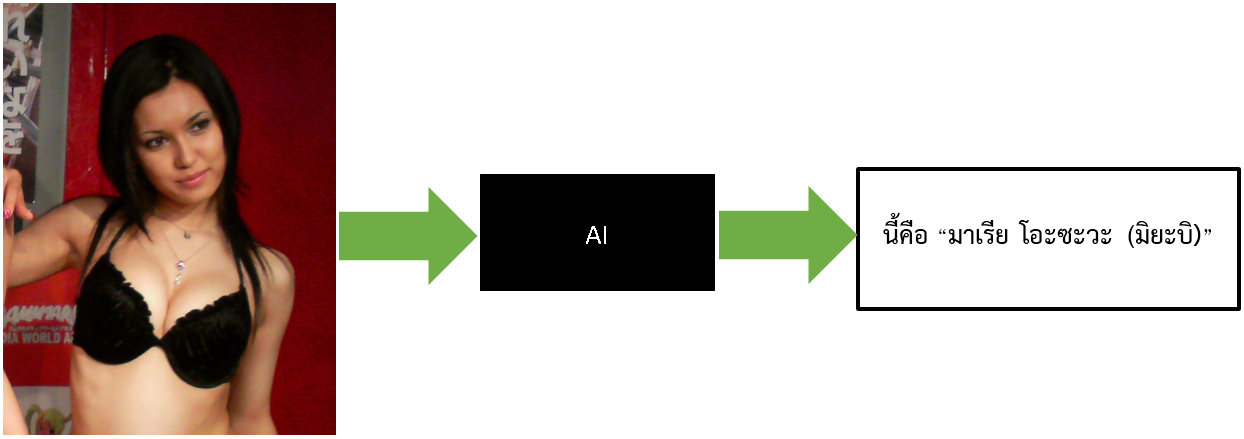
คำถาม จากภาพตัวอย่างที่ยกมา เราสามารถใช้ AI แยกแยะได้ไหมว่า นี้คือภาพ มิยาบิ
คำตอบ AI ทำได้อยู่แล้ว เรื่องนี้ชิลๆ
ลองดูตัวอย่าง AI ตัวนี้ซิ เป็นของ Yahoo มันแยกแยะภาพโป้ได้ แล้วตาไม่เป็นกุ้งยิงด้วยความแม่นยำสูง แล้วอย่างนี้ทำไม AI จะไม่รู้จักมิยาบิ ล่ะ!
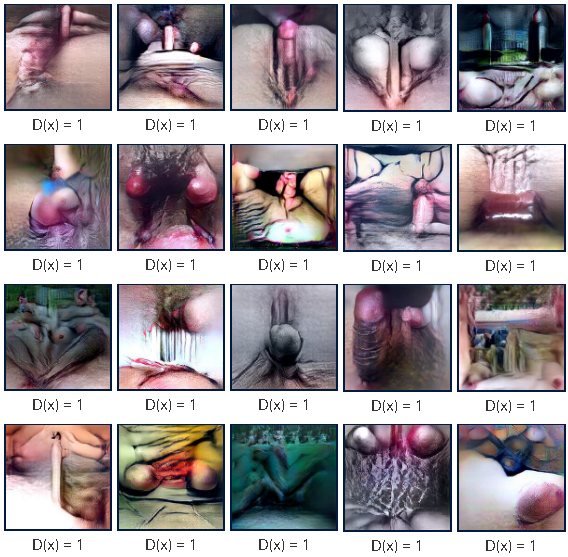
รูปด้านบนคือภาพลามก 18+ นั้นแหละ แต่เป็นภาพที่ผ่านการมองเห็นของ AI จะเหมือนภาพศิลปะหน่อยๆ (ค่าตัวเลข D(x) > 0.8 คือบอกว่าภาพโป้)
แล้วถามต่อ เราสามารถให้ AI แยกแยะตรงไหนได้ว่า นี้คือคิ้ว ตา จมูก หนาอกหน้าใจตูมๆ ของมิยาบิได้ป่ะ แนว AI สายหื่นทำได้ …ทำได้ไหม …บอกหน่อยซิ
คำตอบ (ใจเย็นๆ ไม่ต้องเค้นถามมาก) น่าจะได้นะ เพราะ CNN มันเก่งกาจ ในเรื่องตรวจจับวัตถุในรูปมากๆ
ดูอีกตัวอย่างในรูปข้างล่าง ที่ใช้ AI ตรวจภาพวัตถุหลายอันที่อยู่ในรูปภาพ แล้วแยกแยะได้ว่าอันไหนเป็น ม้า, คน, รถยนต์, หมา, แมว, รถบัส, เรือ แบบ real-time

คำถาม จากภาพมิยาบิต่อ แล้วเราจะใช้ CNN ทำรายงานข่าวมิยาบิ ว่าทำไม เธอถึงลาออกจากวงการ AV ได้ป่ะ
คำตอบ ได้ซิครับ ทำไมจะทำไม่ได้
เอ๊ะไม่ใช่ซิ ผิดๆ เขียนอะไรยากๆ จนเบลอหมดแล้วนิ
ต้องถามว่า สามารถใช้ CNN ตรวจจับวัตถุใน GUI ของโปรแกรม แล้วแยกแยะว่าตรงไหนคือ ปุ่มกด, label, elements ฯลฯ ได้ไหม?
คำตอบ น่าจะทำได้นะ
ด้วยคอนเซปท์ที่ผมเล่ามา Vision Model ของ pix2Code จึงใช้โมเดลแบบ CNN รับภาพหน้าจอ GUI เข้าไป โดยมีรายละเอียดดังนี้
- ภาพจะถูกปรับขนาดให้เล็กลงมา 256 x 256 pixel
- ข้อมูลแต่ละ pixel ในรูปภาพ ซึ่งก็คือค่าตัวเลข Red,Green, Blue จะมีการปรับสเกล (Normalized) ก่อนส่งเข้าไปใน Vision Model
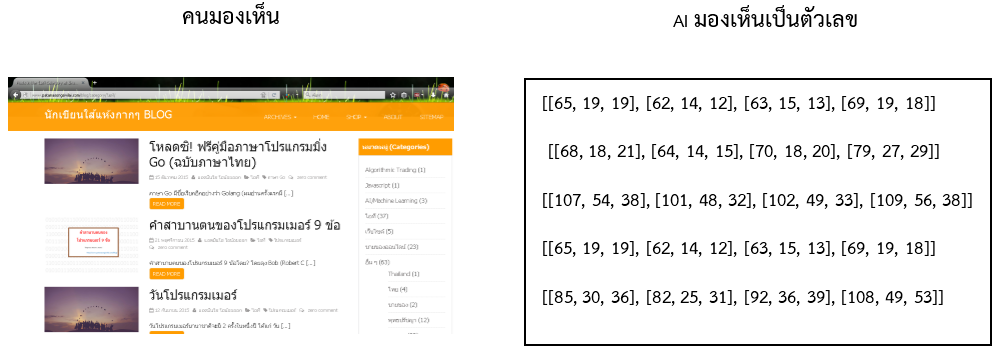
ภาพซ้ายมือเป็นหน้าเว็บ ซึ่งคนสามารถมองเห็นได้ แต่ AI มันคือคอมพิวเตอร์ มองเห็นภาพเป็นแค่ชุดตัวเลข (ค่าสีในรูป ยังไม่ถูกทำ normalized)
Language Model
ไส้ในของ pix2Code ก้อนเบอร์ 2 (รูปก้อนหน้านี้) จะใช้โมเดลที่ชื่อ Language Model
โดยเบื้องหลังมันเป็น Neural Network ประเภท LSTM (Long-term memory) โมเดลประเภทนี้มันเก่งตรงที่ …ถ้ารู้ว่าชุดลำดับข้อมูลก่อนหน้าคืออะไร ก็สามารถทำนายข้อมูลตัวถัดไปได้ เช่น งานที่ให้ AI สร้างข้อความขึ้นมา โดยอาศัยชุดข้อความก่อนหน้า
ลองยกตัวอย่างประโยคนี้
ฉันเป็นคนไทย ดังนั้นฉันจึงพูดภาษาไทย
เมื่อป้อนประโยคดังกล่าวเข้าไปใน LSTM ดังรูปข้างล่าง

จากรูปเมื่อป้อนข้อความ ฉัน เป็น คน ไทย ดัง นั้น ฉัน จึง พูด ภาษา
LSTM ก็จะทำนายคำถัดไปได้ว่าคือ ไทย …ซึ่งนี้คือความเก่งกาจของ neural network ประเภทนี้อยู่แล้ว
แล้วถ้าสมมติมีประโยคถูกป้อนเข้ามาเป็น (ภาษา HTML)
<head> สวัสดีครับ
คำถาม LSTM สามารถทำนายว่าข้อความถัดไปเป็น </head> (tag ปิด)ได้หรือไม่?
คำตอบ ทำได้แน่นอน
คำถาม อ้าว! อย่างนี้ก็เอามาใช้เขียนโค้ดภาษา HTML หรือภาษาโปรแกรมมิ่งอื่นๆ …มีความเป็นไปได้ไหม?
คำตอบ ใช่ …มีความเป็นไปได้ ที่จะเอามันมาช่วยเขียนโค้ดอัตโนมัติให้เรา
อันนี้เป็นตัวอย่างบล็อกของคุณ Andrej Karpathy ที่ใช้ AI เขียนหนังสือ บทความ Wikipedia, Shakespeare, Paper math(ปลอม), หรือที่เด็ดสุดคือแม้แต่โค้ดคอมพิวเตอร์ (ปลอม) ก็เขียนได้ โดยการป้อนอินพุตเป็น text จำนวนมาก ให้มันอ่าน
(เขาใช้ neural network 3 ประเภทได้แก่ RNN, LSTM และ GRU ซึ่งเป็นตระกูลเดียวกัน ที่เก่งในการเรียนรู้ข้อมูลแบบมีลำดับ หรือ sequence เอาโมเดลทั้ง 3 แบบ มาทดลองรัน)
รูปข้างล่างป็นตัวอย่าง AI เขียนหนังสือ โดยเรียนรู้งานเขียนของเชกสเปียร์ (Shakespeare) เทพเกิ๊น

รูปข้างล่างเป็นตัวอย่าง AI เขียนโค้ดภาษา C โดยเรียนรู้ซอร์สโค้ดของ Linux อัยย่ะ เก่งเกินไปแล้ว (โค้ดยังใช้งานไม่ได้นะ ยังคอมไพล์ไม่ผ่าน)
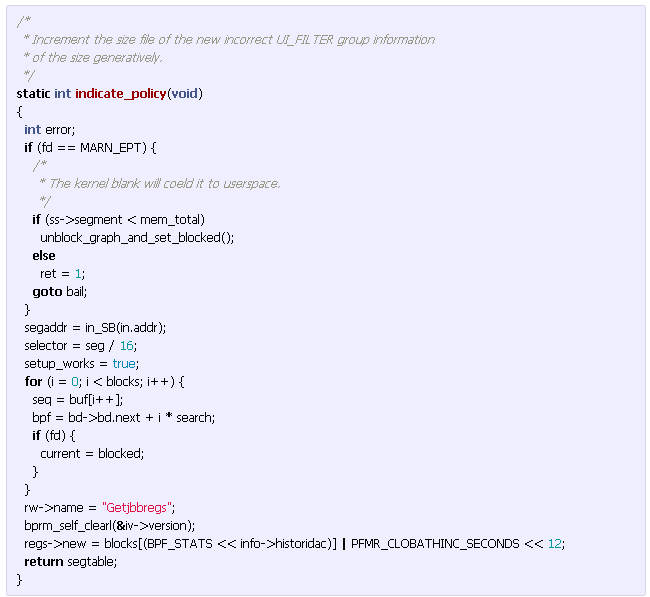
แต่งานของคุณ Andrej Karpathy พวกนี้ ใช้ AI เรียนรู้จาก Text ไม่ใช่รูปภาพนะ
เอาเป็นว่า LSTM ดูเหมาะจะนำมาใช้สร้างโค้ดคอมพิวเตอร์อัตโนมัติ แล้วกันเนอะ
ด้วยเหตุนี้ Language Model ของ pix2Code จึงใช้โมเดลแบบ LSTM รับข้อมูลเข้ามาเป็นลำดับของ tokens ในภาษา DSL โดยมีรายละเอียดดังนี้
- tokens จะต้องถูกเข้ารหัสด้วยวิธี one-hot encoding ก่อน
- tokens ที่เข้าไปใน Language Model จะเข้าทีละชุด ชุดละ 48 ตัว
โมเดลรวมข้อมูล
ไส้ในของ pix2Code ก้อนเบอร์ 3 (รูปก้อนหน้านี้) จะใช้โมเดลที่ชื่อ “โมเดลรวมข้อมูล”
ก่อนอื่นผมขอให้ดูงานวิจัยของ Google ที่ใช้ AI อ่านรูปภาพ แล้วสร้างข้อความบรรยายรูปนั้น (ตามที่กล่าวมาก่อนหน้านี้)

จากสามภาพซ้ายมือสุดข้างบน มีไว้สอน AI ให้ฉลาด เมื่อ AI เจอรูปภาพฝั่งขวามือเป็นหมา 2 ตัว ที่ไม่เคยเจอมาก่อน AI ก็ฉลาดพอที่จะบรรยายรูปนี้ได้
ซึ่งถอดความแปลไทย ที่ AI บรรยายได้ว่า
หมาตัวหนึ่งกำลังนั่งอยู่ริมชายหาดใกล้กับหมาอีกตัวหนึ่ง
เขียนเก่งนะเนี่ย จะเทพไปถึงไหนฟ่ะ!
ลองดูไส้ใน AI ของ Google ที่ว่านี้ก่อน
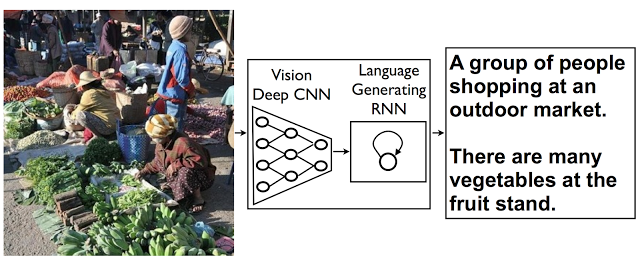
จากภาพข้างบน
- จะเห็นรูปซ้ายมือเป็น input ถูกส่งเข้าไปในกล่องสี่เหลี่ยมตรงกลาง
- ส่วนกรอบขวามือคือ output ที่เป็นข้อความบรรยายรูปภาพ …ถอดความแปลเป็นไทยได้ว่า “กลุ่มคนที่ช๊อปปิ้งในตลาดกลางแจ้ง มีผักผลไม้หลายชนิดวางขาย”
- ส่วนกล่องสี่เหลี่ยมตรงกลางคือ AI นี้แหละ ที่เขาฉาย x-rays ให้เห็นโครงสร้างไส้ในคร่าวๆ
แต่จะให้ลองสังเกตกล่องตรงกลางที่เป็น AI ให้ดีๆ เขาใช้เทคนิค CNN บวกกับ LSTM (ผสมผสานกัน)
โดยใช้ CNN อ่านรูป เมื่อได้ output ออกมา ก็ส่งต่อไปให้ LSTM ใช้บรรยายเป็นข้อความ
แต่ของ pix2Code จะเปลี่ยนจากข้อความตัวหนังสือ มาเป็นบรรยายเป็นโค้ดแทนไงละ
ซึ่งงานวิจัย pix2Code ก็ใช้วิธีผสมผสาน ด้วยการรวม 2 โมเดล Vision model (CNN) กับ Language model (LSTM) เข้าด้วยกัน แต่รายละเอียดเชิงลึกจะแตกต่างจาก Google พอควรนะ ตามรูปข้างล่าง
จากรูป pix2Code ข้างบน จะอธิบายก้อนหมายเลข 1, 2 และ 3 ได้คร่าวๆ ดังนี้
- Vision Model (หมายเลข 1) ใช้อ่านรูปภาพ GUI หน้าจอโปรแกรม แล้วได้ output เป็น p (ตามรูป)
- Language Model (หมายเลข 2) ใช้เดาว่า token ที่จะสร้างขึ้นมาคืออะไร แล้วได้ output เป็น qt (ตามรูป)
- output จาก 2 โมเดล จะเสมือนถูกเข้ารหัส แล้วนำมารวมกัน ก่อนจะส่งไปถอดรหัสด้วย โมเดลรวมข้อมูล (หมายเลข 3 ทำหน้าที่เป็น decoder) แล้วได้ output ออกมาเป็น token (ที่ AI ทำนายออกมา ถ้าในรูปคือ yt)
เรื่อง pix2Code ยังมีต่ออีกนะ (ยังไม่จบเหรอเนี่ย)
pix2Code หรือกล่องสีเทา ยังมีประเด็นเรื่อง input ที่เป็น tokens 48 ตัว ที่เข้าไปในฝั่ง Language model
เพราะ tokens 48 อัน ไม่ได้ป้อนเข้าไปในกล่องสีเทาทีเดียวจบซะที่ไหน? มันป้อนหลายรอบ และหลายชุด tokens (เขียนชักงง ให้ดูตัวอย่างแล้วกัน)
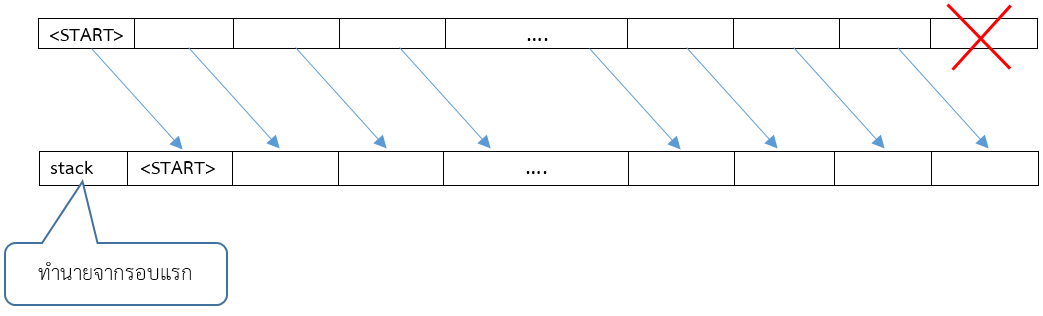
Token รอบแรก
เริ่มต้นจะกำหนด tokens ตั้งต้นว่างๆ 47 ตัว เป็นแถวเรียงขึ้นมาก่อน แต่ token ตัวสุดท้ายจะกำหนดเป็น <START> (ให้มองจากซ้ายไปขวา)
![]()
เมื่อชุด tokens ทั้ง 48 อันตั้งต้นนี้ เข้าไปในกล่อง pix2Code สีเทา
output ที่ได้ ก็คือค่า token ที่กล่องสีเทาทำนายได้ (output จากโมเดลรวมข้อมูล) อย่าลืมว่ายังมีภาพหน้าจอ GUI ซึ่งเป็น input อีกก้อน เป็นตัวช่วยทำนายอีกแรง
ถ้าสมมติรอบแรก กล่องสีเทาทำนายเป็นคำว่า
stack
ลำดับ tokens ชุดต่อไปที่จะเข้ากล่องสีเทา จะเป็นดังหัวข้อถัดไป
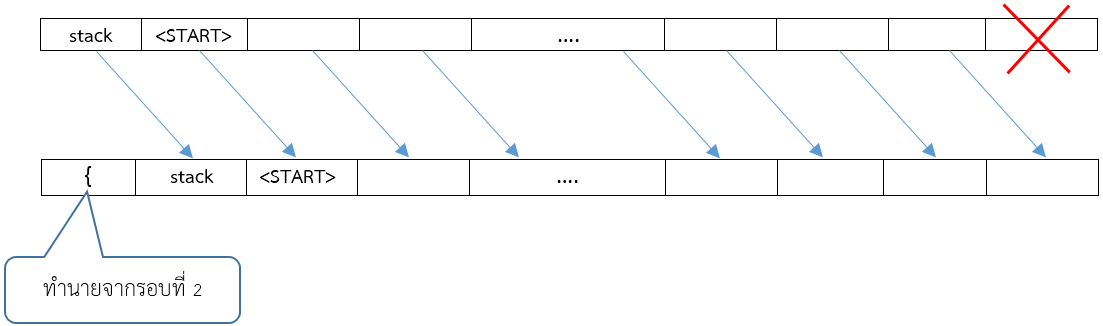
ชุด tokens รอบ 2
คำว่า stack ก็จะไปต่อท้าย <START> ก่อนหน้านี้
ส่วน <START> ก็จะขยับเลื่อนไปอยู่ด้านหน้าอีกช่องหนึ่ง ส่วน token ตัวแรกก็จะไม่ถูกใช้งานแหละ ดังรูป (ให้มองจากซ้ายไปขวา)
ถ้าสมมติรอบ 2 นี้ กล่องสีเทาทำนายได้ว่าเป็นปีกกาเปิด
{
ลำดับ tokens ชุดต่อไปที่จะเข้ากล่องสีเทา จะเป็นดังหัวข้อถัดไป
ชุด tokens รอบ 3
คำว่า { ก็จะไปต่อท้าย stack
ส่วน <START> กับ stack ก็จะขยับเลื่อนไปอยู่ด้านหน้าอีกช่องหนึ่ง ส่วน token ตัวแรกก็จะไม่ถูกใช้งานแหละ
อารมณ์เหมือนเรามองเห็นข้อความผ่านทางหน้าต่าง ที่มีขนาด 48 ช่อง แล้วหน้าต่างก็เลื่อนไสด์จากซ้ายไปขวา
อธิบายแบบนี้ไม่รู้โอเคเปล่า
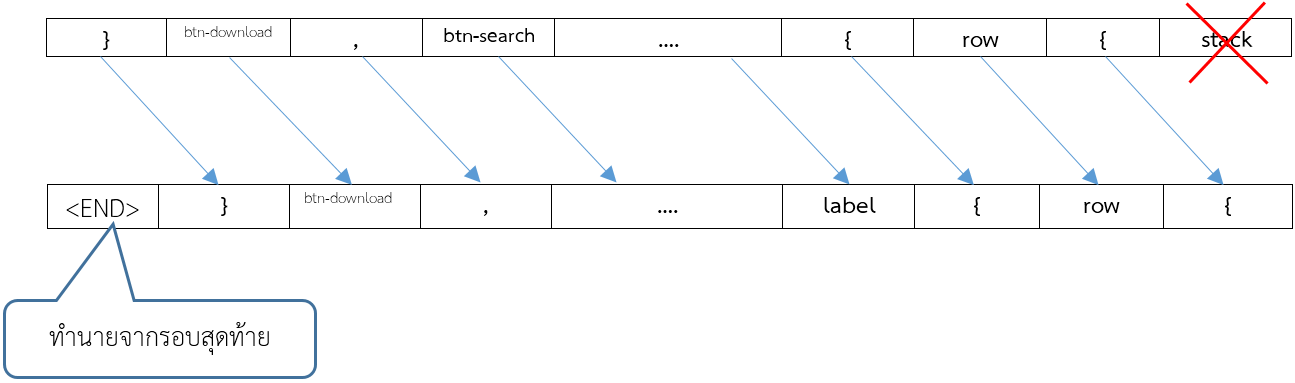
กล่องสีเทาจะสร้างชุด tokens ของภาษา DSL ทำเป็นแบบนี้ซ้ำไปเรื่อยๆ
คำถาม แล้วจะหยุดทำงานเมื่อไร?
ในกรณีนี้จะหยุดเมื่อกล่องสีเทา เขียนคำว่า <END> ออกมา ก็จะหมายถึงเขียนโค้ดเสร็จแล้ว ดังรูปข้างล่าง
แต่อย่าลืมว่า tokens ทั้งหมด 48 อัน ที่จะเข้าไปในกล่องสีเทา จะถูกเข้ารหัสเสียก่อน (one-hot encoding) ดังรูปข้างล่าง
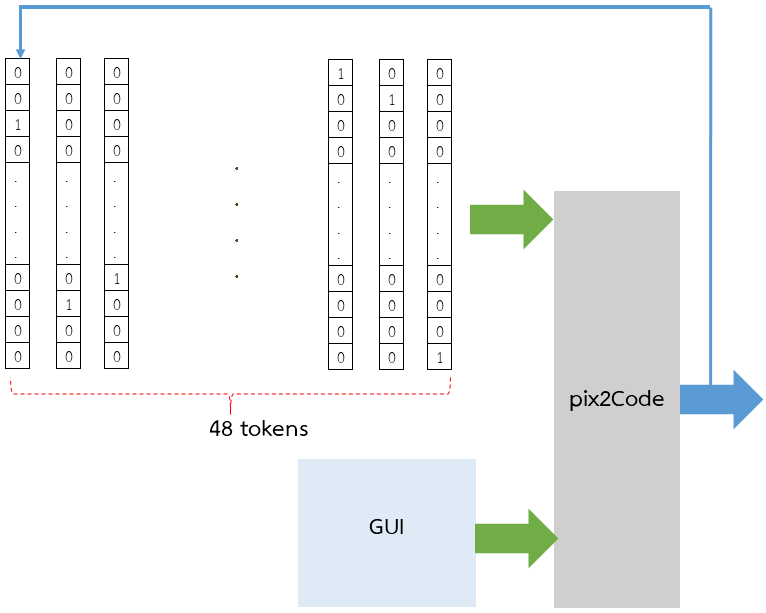
สรุปหลักการป้อน input คร่าวๆ
- GUI หน้าจอโปรแกรม ที่ใช้เป็น input เข้ากล่องสีเทา จะมีแค่อันเดียว
- ส่วน tokens ที่ถูกเข้ารหัส จะเข้าไปทีละ 48 ตัว โดย token ลำดับหลังสุด จะใช้ค่า token ก่อนหน้านี้ ที่ได้จาก output ของกล่องสีเทา ซึ่งจะวนทำแบบนี้ไปเรื่อยๆ จนกล่องสีเทาให้ token ตัวสุดท้ายเป็น <END>
การแปลงร่าง DSL ขั้นสุดท้าย
เมื่อ pix2Code หรือกล่องสีเทา มันสร้างโค้ด DSL ออกมาเรียบร้อย แน่นอนยังเอาไปใช้ไม่ได้ ต้องมา comply ให้กลายเป็นโค้ดโปรแกรมที่ใช้งานได้บน iOS, Android และเว็บ (HTML/CSS)
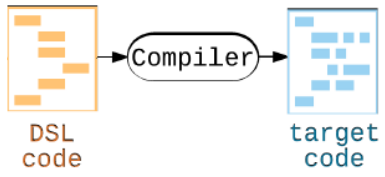
***รายละเอียดการ comply โค้ดของภาษา DSL เป็นภาษาโปรแกรมมิ่งอื่น …งานวิจัยไม่ได้กล่าวถึงว่าทำอย่างไรนะ
***ส่วนเนื้อหาเชิงลึกของ paper ผมขอตัดจบไม่ลงลึกนะครับ เพราะคิดว่าอนาคต มันคงพัฒนาเทคนิคไปมากกว่านี้ แถมไส้ในกล่อง pix2Code ก็อาจเปลี่ยนแปลงได้ด้วย หรืออาจมีเทคนิคอื่นที่ดีกว่านี้ …อันนี้แค่เล่าถึงคอนเซปต์ในการสร้างให้เห็นไอเดีย เผื่อใครสนใจไปพลิกแพลงต่อได้
ตัวอย่างผลลัพธ์จากการทดลอง
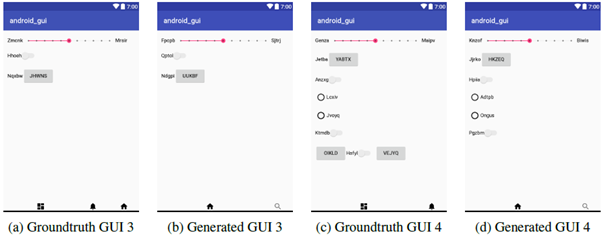
ภาพ a คือหน้าจอ ส่วน b เป็นภาพหน้าจอที่ได้จากโค้ดของ AI (layout ก็เกือบเหมือนนะ ตรงไอคอนล่างๆ ที่แตกต่าง)
ภาพ c คือหน้าจอ ส่วน d เป็นภาพหน้าจอที่ได้จากโค้ดของ AI (layout ไม่ตรงเหมือนกันนะ)
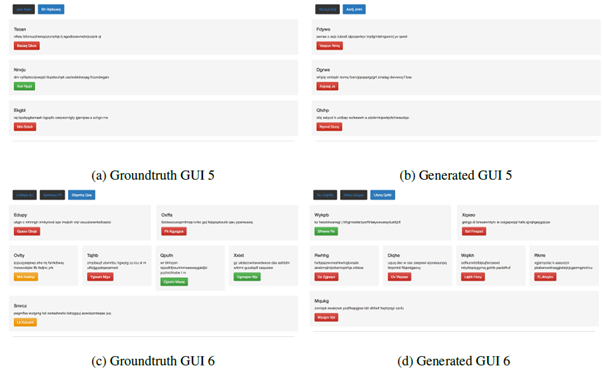
ที่มารูป[1]
ภาพ a คือหน้าจอ ส่วน b เป็นภาพหน้าจอที่ได้จากโค้ดของ AI (layout เกือบเหมือน)
ภาพ c คือหน้าจอ ส่วน d เป็นภาพหน้าจอที่ได้จากโค้ดของ AI (layout เกือบเหมือน)
***ข้อความบนหน้าจอ (text) งานวิจัยนี้ไม่ได้สนใจนะ (ช่างมันไปก่อน) สนใจแต่ layout ว่าถูกต้องหรือไม่
วิธีการติดตั้งและรันโปรเจค pix2code
การติดตั้งจะเป็นแบบคอมมานไลน์ทั้งหมดนะครับ
การติดตั้ง
วิธีใช้งานจะเป็นแบบคอมมานไลน์ทั้งหมดนะครับ
1) แนะนำให้ลง Anaconda ซึ่งเป็นแพลตฟอร์มสำหรับงาน machine learning และ Deep learning โดยเฉพาะ ทำให้เราสามารถใช้ python ได้ ลิงค์ดาวน์โหลด https://www.anaconda.com/download/
2) ดาวน์โหลดแพ็กเกจเป็น zip จากโปรเจคต้นตำรับ
https://github.com/tonybeltramelli/pix2code
ดาวน์โหลดเสร็จก็แตกไฟล์ด้วยครับ
ถ้าใครใช้ git เป็น ก็ใช้คำสั่งบนคอมมานไลน์
git clone https://github.com/tonybeltramelli/pix2code.git
เดี่ยวโค้ดของโปรเจคจะดาวน์โหลดมาอยู่ที่เครื่องเรา (อย่าลืมต่อเน็ตด้วย)
3) cd ไปในโฟลเดอร์ pix2code
ควรเห็นโฟลเดอร์ย่อยพวกนี้
pix2code |-- compiler\ |-- datasets\ |-- model\ |- requirements.txt
4) ทำการติดตั้งมอดูลต่างๆ ด้วยคำสั่ง
pip install -r requirements.txt
การเตรียมข้อมูลไว้สอน
1) ให้ไปที่โฟลเดอร์ datasests
cd datasets
2) แล้วแตกไฟล์ออกมาด้วยคำสั่ง
zip -F pix2code_datasets.zip --out datasets.zip unzip datasets.zip
ถ้าบนวินโดวส์ก็แตกไฟล์ pix2code_datasets.zip ได้โดยตรง
3) ไปที่โฟลเดอร์ model คำสั่งสร้าง datasets อยู่ที่นั้น
cd ../model
4) แล้วสร้าง datasets ที่จะเอาไว้ใช้สอนโมเดล ด้วยคำสั่งเหล่านี้
# split training set and evaluation set while ensuring no training example in the evaluation set # usage: build_datasets.py <input path> <distribution (default: 6)> ./build_datasets.py ../datasets/ios/all_data ./build_datasets.py ../datasets/android/all_data ./build_datasets.py ../datasets/web/all_data
# transform images (normalized pixel values and resized pictures) in training dataset to numpy arrays (smaller files if you need to upload the set to train your model in the cloud) # usage: convert_imgs_to_arrays.py <input path> <output path> ./convert_imgs_to_arrays.py ../datasets/ios/training_set ../datasets/ios/training_features ./convert_imgs_to_arrays.py ../datasets/android/training_set ../datasets/android/training_features ./convert_imgs_to_arrays.py ../datasets/web/training_set ../datasets/web/training_features
หมายเหตุ บนวินโดวส์ รันคำสั่งพวกนี้โดยไม่ต้องมี ./ นำหน้าคำสั่ง แต่บน linux ต้องมีนะครับ
กาสอนโมเดลให้ฉลาด
1) ให้สร้างโฟลเดอร์ bin (อยู่ใต้โฟลเดอร์ pix2code)
mkdir bin
2) แล้วไปที่โฟลเดอร์ model คำสั่งที่ใช้สอนจะอยู่นั้น
cd model
3) รันคำสั่ง มีให้เลือก 4 แบบ
# provide input path to training data and output path to save trained model and metadata # usage: train.py <input path> <output path> <is memory intensive (default: 0)> <pretrained weights (optional)> ./train.py ../datasets/web/training_set ../bin
# train on images pre-processed as arrays ./train.py ../datasets/web/training_features ../bin
# train with generator to avoid having to fit all the data in memory (RECOMMENDED) ./train.py ../datasets/web/training_features ../bin 1
# train on top of pretrained weights ./train.py ../datasets/web/training_features ../bin 1 ../bin/pix2code.h5
ตัวโปรเจคแนะนำให้ใช้คำสั่งแบบที่ 3 นะครับ
แต่การสอนจะใช้เวลานานมากกกกกกกกกกก สุดท้ายจะได้ไฟล์ pix2code.h5 อยู่ที่ไดเรคเทอรี่ bin ที่เราสร้างขึ้น
แปลงภาพหน้าจอเป็นภาษา DSL
1) สร้างโฟลเดอร์ code (อยู่ใต้โฟลเดอร์ pix2code)
mkdir code
2) ไปที่โฟลเดอร์ model ซึ่งจะเก็บคำสั่งเอาไว้
cd model
3) การรันคำสั่งจะให้เลือก 3 แบบ
# generate DSL code (.gui file), the default search method is greedy # usage: generate.py <trained weights path> <trained model name> <input image> <output path> <search method (default: greedy)> ./generate.py ../bin pix2code ../gui_screenshots ../code
# equivalent to command above ./generate.py ../bin pix2code ../gui_screenshots ../code greedy
# generate DSL code with beam search and a beam width of size 3 ./generate.py ../bin pix2code ../gui_screenshots ../code 3
หมายเหตุ gui_screenshots คือโฟลเดอร์เก็บรูปภาพหน้าจอเรานะครับ ถ้าเก็บภาพไว้ที่ไหนก็ระบุ path ให้ตรงด้วย
หรือจะรันโดยใช้รูปภาพอันเดียวเลย ก็ย่อมทำได้ ก็จะมี 3 รูปแบบ คำสั่งเช่นกัน
# generate DSL code (.gui file), the default search method is greedy # usage: sample.py <trained weights path> <trained model name> <input image> <output path> <search method (default: greedy)> ./sample.py ../bin pix2code ../test_gui.png ../code
# equivalent to command above ./sample.py ../bin pix2code ../test_gui.png ../code greedy
# generate DSL code with beam search and a beam width of size 3 ./sample.py ../bin pix2code ../test_gui.png ../code 3
หมายเหตุ test_gui.png คือรูปภาพจะอยู่ใต้โฟลเดอร์ pix2code ถ้าอยู่ที่อื่นก็ระบุ path ให้ถูกต้องด้วย
สำหร้าโค้ดของภาษา DSL ที่ AI สร้างออกมาอยู่ในโฟลเดอร์ code นะครับ
การคอมไพล์จาก DSL เป็นภาษาบนเว็บ, iOS และ Android
1) คำสั่งคอมไพล์อยู่ในโฟลเดอร์ compiler
cd compiler
วิธีคอมไพล์จะมี 3 แบบได้แก่ บนเว็บ iOS และ แอนดรอย์ส์
# compile .gui file to Android XML UI ./android-compiler.py <input file path>.gui
# compile .gui file to iOS Storyboard ./ios-compiler.py <input file path>.gui
# compile .gui file to HTML/CSS (Bootstrap style) ./web-compiler.py <input file path>.gui
หมายเหตุ <input file path> คือชื่อ path ของไฟล์ *.gui ปกติจะถูกสร้างอยู่ใต้โฟลเดอร์ code เช่น เมื่อรูปภาพเราเป็น test_gui.png ก็จะได้ไฟล์ภาษา DSL ออกมาชื่อ test_gui.gui เป็นต้น
5) ผลลัพธ์จากการคอมไพล์ด้วยภาษา DSL เป็น HTML/CSS จะอยู่ในโฟลเดอร์ code เช่นเดียวกับไฟล์ *.gui
แนะนำเพิ่มเติม
มีหลายโปรเจคที่นำเอา pix2code ไปขยายต่อ ถ้าสนใจนะ ก็เช่น
- https://github.com/emilwallner/Screenshot-to-code แต่เขาจะแปลงเป็น HTML/CSS อย่างเดียว
- https://github.com/fjbriones/pix2code2 ซึ่งเขาดัดแปลงมาจาก pix2code อีกที ตัวโมเดลจะถูกสอนเสร็จเรียบร้อย ลองเล่นได้เลยครับ แต่เขาจะแปลงเป็น HTML/CSS อย่างเดียว
- https://github.com/ashnkumar/sketch-code เขาจะแปลงเป็น HTML/CSS อย่างเดียว …เดี่ยวจะแนะนำโปรเจคนี้เพิ่มเติมในหัวข้อถัดไปครับ เพราะมีโมเดลที่ถูกสอนเสร็จเรียบร้อย แต่เขาจะแปลงเป็น HTML/CSS อย่างเดียว
การติดตั้งโปรเจค sketch-code
เนื่องจากโปรเจค pix2code อาจติดตั้งยุ่งยาก ผมเลยอยากจะแนะนำโปรเจคนี้ sketch-code ซึ่งเขาก็นำงาน pix2code และ Screenshot-to-code
สำหรับ sketch-code โปรเจคนี้ เราแค่วาดแบบร่างหน้าจอด้วยมือเปล่า ก็จะแปลงเป็นภาษา HTML/CSS ได้แหละ (โปรเจคนี้ได้หน้าเว็บอย่างเดียว) โดยเขาจะมีโมเดลที่ถูกสอนเรียบร้อย เรามาลองเล่นได้เลย
วิธีใช้งานและติดตั้ง จะเป็นแบบคอมมานไลน์ทั้งหมดนะครับ
1) แนะนำให้ลง Anaconda ซึ่งเป็นแพลตฟอร์มสำหรับงาน machine learning และ Deep learning โดยเฉพาะ ทำให้เราสามารถใช้ python ได้ ลิงค์ดาวน์โหลด https://www.anaconda.com/download/ (ถ้าลงแล้วจากหัวข้อที่แล้วก็ข้ามไปได้ครับ)
2) ดาวน์โหลดแพ็กเกจเป็น zip จากโปรเจคต้นตำรับ
https://github.com/ashnkumar/sketch-code
ดาวน์โหลดเสร็จก็แตกไฟล์ด้วยครับ
ถ้าใครใช้ git เป็น ก็จะใช้คำสั่งบนคอมมานไลน์
git clone https://github.com/ashnkumar/sketch-code.git
เดี่ยวโค้ดของโปรเจคจะดาวน์โหลดมาอยู่ที่เครื่องเรา (อย่าลืมต่อเน็ตด้วย)
3) ทำการติดตั้งมอดูลต่างๆ ด้วยคำสั่ง
pip install -r requirements.txt
4) ไปดาวน์โหลดข้อมูลสอน (datasets) และโมเดล (ค่าน้ำหนัก) ที่ถูกสอนเรียบร้อยแล้ว โดย cd ไปที่ไดเรคเทอรี่
cd sketch-code\scripts\
ตอนนี้ควรอยู่ในไดเรคเทอรี่ sketch-code\scripts\
แล้วให้ดาวน์โหลดข้อมูลสอน ถ้าใน Linux ก็ให้รันสคริปต์
sh get_data.sh
ถ้าใช้วินโดวส์ ก็ดาวน์โหลดด้วยมือครับ
http://sketch-code.s3.amazonaws.com/data/all_data.zip
แล้วแตกไฟล์ zip ไปที่โฟลเดอร์ data/all_data ก็จะได้หน้าตาโครงสร้างไดเรคเทอรี่ประมาณเนี่ย
sketch-code |- data |- all_data\ ไฟล์ที่แตกจาก all_data.zip
ถ้าเราไม่อยากสอน AI ใหม่ ก็ไม่ต้องดาวน์โหลด all_data.zip ก็ได้ครับ ข้ามไปได้เลยครับ
ยังอยู่ที่ sketch-code\scripts\ เพราะต้องรันสคริปต์ดาวนโหลดโมเดล AI ที่ถูกสอนเรียบร้อยแล้ว
ถ้าใน Linux ก็ให้รันสคริปต์ดังนี้
sh get_pretrained_model.sh
แต่ถ้าใช้วินโดวส์ ก็ดาวน์โหลดด้วยมือครับ จะมีสองไฟล์
http://sketch-code.s3.amazonaws.com/model_json_weights/model_json.json
http://sketch-code.s3.amazonaws.com/model_json_weights/weights.h5
ให้เก็บ 2 ไฟล์ดังกล่าวไว้ที่โฟลเดอร์ bin ก็จะได้หน้าตาโครงสร้างไดเรคเทอรี่ ภาพรวมใหญ่ประมาณเนี่ย
sketch-code |- src |- scripts |- examples |- data |- all_data\ ไฟล์ที่แตกจาก all_data.zip |- bin |- model_json.json |- weights.h5
5) วิธีการรัน ให้ไปที่โฟลเดอร์ sketch-code\src เพราะไฟล์ที่ใช้รันคือ convert_single_image.py แล้วสั่งรันด้วยคำสั่งต่อไปนี้
python convert_single_image.py --png_path ../examples/drawn_example1.png \ --output_folder ./generated_html \ --model_json_file ../bin/model_json.json \ --model_weights_file ../bin/weights.h5
โดย /examples/drawn_example1.png คือภาพตัวอย่างหน้าจอที่จะทำการแปลงโค้ด (ร่างด้วยมือ)
ส่วนผลลัพธ์เก็บไว้ที่โฟลเดอร์ generated_html ซึ่งจะอยู่ใต้ src อีกที
สำหรับเครื่องหมาย \ ในคำสั่ง คือการเคาะลงบรรทัด ถ้ารันในวินโดวส์อาจไม่ได้ ก็ให้ลบ \ ทิ้งไป แล้วให้คำสั่งอยู่ในบรรทัดเดียวกันหมด จะได้คำสั่งยาวๆ ประมาณนี้
python convert_single_image.py --png_path ../examples/drawn_example1.png --output_folder ./generated_html --model_json_file ../bin/model_json.json --model_weights_file ../bin/weights.h5
ผลการรันก็จะได้รูปข้างล่าง โดยซ้ายมือเป็นตัวอย่างร่างหน้าจอด้วยมือ ที่ถูกแปลงให้ได้โค้ดหน้าจอ HTML/CSS ดังภาพขวามือ
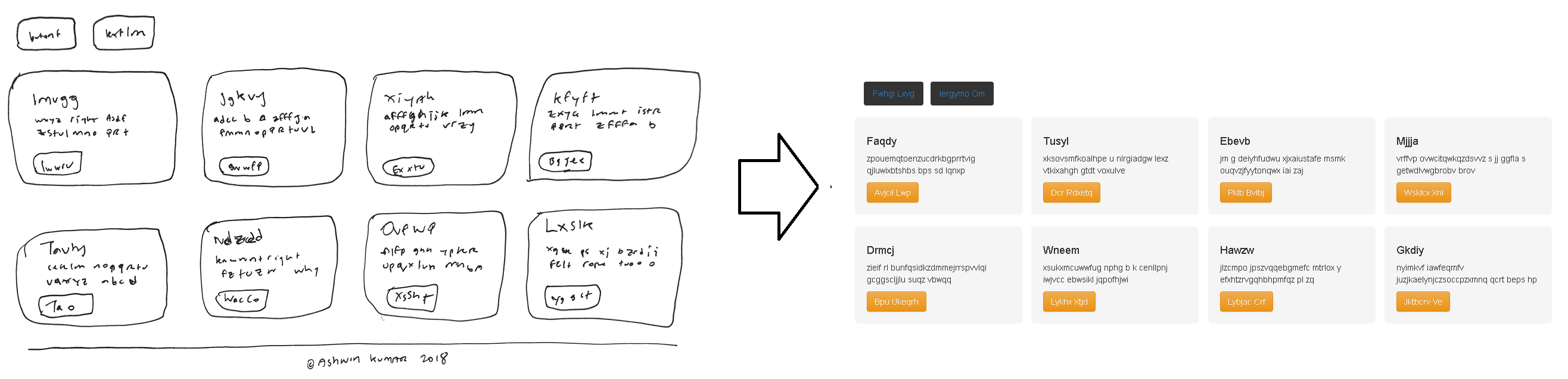
6) ส่วนคำสั่งๆ อื่น เช่น เทรนหรือสอนโมเดล ไปดูเพิ่มเติมในลิงค์ต้นฉบับนะครับ
https://github.com/ashnkumar/sketch-code
ก่อนจากกันไป
ที่มาวีดีโอประกอบ (ไม่เกี่ยวกับ paper)https://pixabay.com/th/videos/รหัสแหล่งที่มา-จอมอนิเตอร์-การแสดงผล-171/
ถามว่าโปรเจคนี้สำเร็จขึ้นมา 100% มันจะมาแย่งงานโปรแกรมเมอร์ฝั่ง Front-end ไหม
- คุณ Tony Beltramelli เขียนบอกว่า อนาคตเขาไม่เชื่อ AI จะมาแทนคน แต่จะจับมือร่วมกับคนเสียมากกว่า
- โปรเจคนี้มีจุดมุ่งหมายเพื่อลดช่องว่าง หรืองานระหว่างนักออกแบบ UI/UX และโปรแกรมเมอร์ฝั่ง Front-end เสียมากกว่า ไม่ใช่มาแทนที่ใคร
- คือเราต้องเปลี่ยนวิธีคิดในการทำงาน อะไรที่ทำซ้ำๆ เป็นอุปสรรคต่อการสร้างนวัตกรรมใหม่ๆ แทนที่โปรแกรมเมอร์ต้องมาโค้ดดิ่งอะไรซ้ำๆ หน้า UI สู่เสียเวลาทุ่มเท มุ่งเขียนโปรแกรมในส่วนหลักๆ ไม่ดีกว่าเหรอ ตอนนี้ให้คุณลืมการเขียนโค้ดฝั่ง UI ไปได้เลย
- ส่วนฝั่งดีไซน์ออกแบบ ก็มีอิสระเต็มที่ในการคิดสร้างสรรค์ออกแบบหน้าจอ ให้แก่ผู้ใช้งาน
ถึงต่อให้งานวิจัยนี้สำเร็จ 100% …AI ตัวนี้ก็คงเป็นแค่ผู้ช่วยลดงานโปรแกรมเมอร์มากกว่า เพราะไส้ในโค้ดฝั่งหน้าจอ เช่น จะให้ปฏิสัมพันธ์ผู้ใช้อย่างไร กดปุ่มนี้จะเกิดอะไรขึ้น จะติดต่อฐานข้อมูล หรือทำงานอะไร หรือกดเมนูปุ๊บ แล้วจะให้รายการอะไรโผล่ออกมาให้ผู้ใช้เห็น เป็นต้น
ซึ่งงานเขียน logic เพิ่มพวกนี้ ก็คงให้มนุษย์โลกเขียนโค้ดเอง จักรอัจฉริยะ AI ยังเป็นแค่ตัวสำรองคนหนึ่ง (เขียนโครงหน้า Front-end ให้เราเฉยๆ)
สุดท้ายใครอ่านจบได้ ก็ขอบคุณที่อ่านครับ และขออภัยล่วงหน้า ถ้าให้ข้อมูลผิดพลาดบ้างประการ หรืออ่านไม่รู้เรื่อง เพราะแกะมาจากงานของ Tony Beltramelli อีกที บวกกับอ้างอิงจากงานวิจัยคนอื่นด้วยครับ
ขอทิ้งท้ายให้ดูว่าโปรแกรมเมอร์แบบไหน มีโอกาสถูก AI แย่งงานในอนาคต (แหล่งที่มาคือ https://willrobotstakemyjob.com/)
1) ตำแหน่ง Software Developers, Application เสี่ยงโดนแย่งงานต่ำมากแค่ 4.2% สำหรับหน้าที่รับผิดชอบได้แก่
- สามารถพัฒนา สร้าง แก้ไข พวกแอพลิเคชั่น ซอฟต์แวร์ทั่วไป หรือจะเป็นโปรแกรม Utility เฉพาะทาง
- วิเคราะห์ความต้องการ user และพัฒนาโซลูชั่นซอฟต์แวร์
- ออกแบบซอฟต์แวร์ หรือปรับแต่งซอฟต์แว์แก่ลูกค้า โดยมีวัตถุประสงค์เพื่อเพิ่มประสิทธิภาพในการทำงาน
- สามารถวิเคราะห์และออกแบบ Database ภายในขอบเขตงานของแอพนั้นๆ แล้วทำงานตัวคนเดียว หรือทำงานพัฒนา Database เป็นทีมได้
- สามารถดูแลโปรแกรมคอมพิวเตอร์ได้
2) ตำแหน่ง Computer programmerเสี่ยงโดนแย่งงานสูงถึง 48% สำหรับหน้าที่รับผิดชอบได้แก่
- สร้าง แก้ไข ทดสอบโค้ด สร้างฟอรม เขียนสคริปต์ เพื่อรันแอพลิคเคชั่น โปรแกรม
- ทำงานโดยเขียนโค้ดจาก spec ที่โยนออกมาจากคนที่เป็น software developer หรือจากคนอื่น
- แค่ช่วย software developer วิเคราะห์ความต้องการ user และช่วยออกแบบโซลูชั่นซอฟต์แวร์
- แค่ช่วยพัฒนา เขียนโปรแกรมคอมพิวเตอร์เพื่อจัดเก็บ ค้นหา และดึงข้อมูล เอกสาร อะไรพวกนี้
ถ้าไม่อยากโดน AI มาแย่งงาน เราควรเป็นโปรแกรมเมอร์แบบที่ 1 นะครับ โอกาสโดนแย่งงานต่ำมาก ซึ่งแตกต่างจากแบบที่ 2 ตรงที่โปรแกรมเมอร์แบบที่ 1 ต้องคิดเป็น ออกแบบ ตัดสิน แก้ปัญหาได้ ไม่ใช่รับงานตามสั่งอย่างเดียว …ใครที่ทำงานแบบ routine หรือมีรูปแบบตายตัว อนาคต AI สามารถทำงานแทนเราได้
ภาพและข้อมูลบ้างส่วน อ้างอิงจากต้นฉบับ Paper ของคุณ Tony Beltramelli
[1] https://arxiv.org/abs/1705.07962
[2] https://github.com/tonybeltramelli/pix2code
อ้างอิงงานวิจัยและโปรเจค
[3] http://www.primaryobjects.com/bf-programmer-2017.pdf
[4] https://openreview.net/pdf?id=ByldLrqlx
[5] https://research.googleblog.com/2016/09/show-and-tell-image-captioning-open.html
[6] https://github.com/yahoo/open_nsfw
[7] https://arxiv.org/abs/1506.01497
[8] http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[9] https://github.com/fjbriones/pix2code2
แนะนำหนังสือ AI (ปัญญาประดิษฐ์)

“AI ไม่ยาก เข้าใจได้ด้วยเลขม.ปลาย (เนื้อหาภาษาไทย) เล่ม 1”
เขียนโดย แอดมินโฮ โอน้อยออก